GraphRel: Modeling Text as Relational Graphs for Joint Entity and Relation Extraction
Fu, T.-J., Li, P.-H., & Ma, W.-Y. (2019). GraphRel: Modeling Text as Relational Graphs for Joint Entity and Relation Extraction. 1409–1418. https://doi.org/10.18653/v1/p19-1136
这篇论文提出了一个新的模型GraphRel,这个模型是一个端到端的关系提取模型,使用了图卷积网络来抽取命名实体和关系。和之前的模型相比,GraphRel考虑了命名实体和关系之间的相互作用,通过一个关系权重的图卷积网络来更好地提取关系。另外,GraphRel也考虑了线性和依赖结构,以及文本单词对之间的隐式特征。这篇论文在NYT和WebNLG两个公开数据集上对GraphRel进行了评估,结果显示GraphRel具有很高的准确率和召回率,另外F1值也达到了一个新的高度。
论文背景
从文本中提取出带有语义关系的实体对(比如三元组)是信息抽取的中心任务,也能够促进无结构文本自动知识提取。但是目前还有三个关键方面还未完全解决,分别是①端到端的实体识别和关系抽取的联合建模;②重叠关系的预测;③关系之间相互作用的考虑。这篇论文提出了GraphRel,是一个端到端的实体识别和关系抽取的联合模型,也是首次解决关系抽取的三个关键方面问题的模型。
论文模型
GraphRel模型堆叠了一个双向LSTM语句编码器和一个图卷积网络依赖树编码器,以此来针对每一个单词自动化提取隐藏特征。之后GraphRel标注了被识别出的单词和预测到的三元组关系,这个被称为第一阶段的预测。为了更好的预测实体之间的关系,GraphRel采用了两个阶段来进行预测。GraphRel在第二阶段的预测中增加了一个关系权重的图卷积网络,能够有效地考虑关系和实体之间的相互作用。
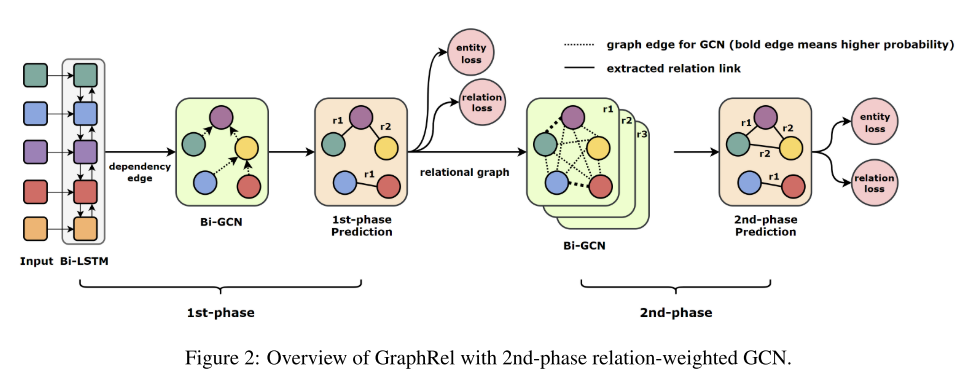
第一阶段预测:在这一阶段预测过程中,模型首先采用双向RNN来提取时序特征,然后使用双向图卷积网络Bi-GCN来进一步提取区域依赖特征。之后基于已经提取出的单词特征,模型预测了每一个单词对的关系和单词实体。模型使用LSTM来作为双向RNN的核,针对每一个单词,模型将它的单词嵌入和POS(part-of-speech)嵌入结合作为初始特征。即
$$
h^0_u = Word(u) ⊕POS(u)
$$
由于原始输入数据中并没有图结构,所以模型使用依赖解析器针对输入的句子创建了一个依赖树。之后模型将依赖树作为输入句子的邻接矩阵,并使用图卷积网络GCN来提取区域依赖特征。另外原始的GCN是针对无向图设计的,不能同时考虑双向的信息,因此这里为了同时考虑输入和输出单词的特征,这个模型使用了双向图卷积网络Bi-GCN。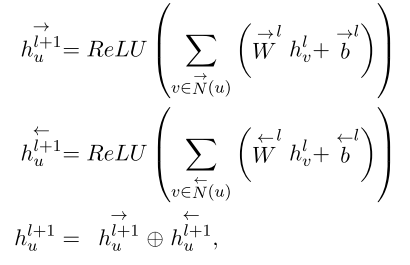
利用双向RNN和双向GCN提取出的单词特征,模型预测了单词实体并针对每个单词对提取出了相应的关系。
单词实体:模型根据单词在一层LSTM的特征预测对单词实体进行预测,并使用离散损失函数来训练这些结果。
关系抽取:模型首先去除了所有依赖边,之后对所有单词对进行预测,针对每一个关系,模型学习了权重矩阵W并计算了关系可能性得分S,之后在对每一个得分应用SoftMax函数,得到每一个关系的概率P,进而确定关系是否有效。
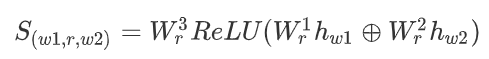
第二阶段预测:在第一阶段中提取出的实体和关系,并不能考虑到他们之间的相互影响,所以为了考虑命名实体和关系之间的相互关系,并且关注文本中所有单词对之间的隐式特征,模型在第二阶段预测中使用关系权重GCN来进行进一步提取信息。在第一阶段之后,模型产生了一个完整的关系权重图。然后第二阶段,在关系图中采用Bi-GCN,将不同的关系的不同重要维度聚合成一个综合的单词特征。第二阶段的Bi-GCN进一步考虑了加权关系传播并针对每一个单词提取出足够多的特征。
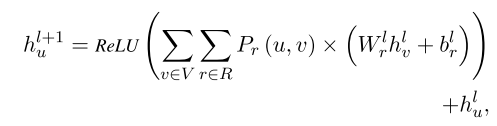
论文实验
论文在NYT和WebNLG数据集上对模型进行了评估,并采用NovelTagging,MultiDecoder作为对比。实验结果显示,GraphRel的F1值相较于之前最好的结果,在NYT上优化了3.2%,在WebNLG上优化了5.8%。同时实验也反映出第二阶段的预测确实可以提取出更多的特征信息。
论文总结
这篇论文提出了一个端到端的关系抽取模型GraphRel,基于图卷积网络联合学习了命名实体和关系的特征信息,并且结合了RNN和GCN来提取时序信息和每一单词的区域依赖信息。此外还考虑了单词对之间的隐式特征信息以及命名实体和关系之间的相互作用。模型经过评估,F1值相较于之前最好的结果有了很大的提升并且达到了关系抽取的SOTA(state-of-the-art)。
Matching the Blanks: Distributional Similarity for Relation Learning
Baldini Soares, L., FitzGerald, N., Ling, J., & Kwiatkowski, T. (2019). Matching the Blanks: Distributional Similarity for Relation Learning. 2895–2905. https://doi.org/10.18653/v1/p19-1279
通用目的关系提取器,能够对任意关系建模,是信息提取的核心。之前提出的一些通用目的关系提取器的方法,比如使用表面形式表示关系的方法,或者联合嵌入表面形式和已有知识图谱中的关系的方法,都不能很好地泛化。这篇论文基于Harris的分布式假说和最近在文本表示方面的进展(Bert模型),仅仅从实体链接的文本中构建了任务无关的关系表示。实验显示,模型即使不使用任何任务的训练数据,在FewRel数据集上的表现也能显著优于之前的方法。此外模型在有监督的关系抽取数据集SemEval 2010 Task8、KBP37、TACRED上也达到了SOTA的效果。
论文背景
通用目的关系提取器,能够对任意关系建模,是信息提取的核心。之前提出的一些通用目的关系提取器的方法,比如使用表面形式表示关系的方法,或者联合嵌入表面形式和已有知识图谱中的关系的方法,都不能很好地泛化。这篇论文基于Harris的分布式假说和最近在文本表示方面的进展(Bert模型),仅仅从实体链接的文本中构建了任务无关的关系表示。
论文采用了Transformer神经网络架构来编码实体对之间的关系,并提出了一种通过Matching-the-blanks来实现无监督的训练关系表示的方法。论文的主要贡献有两个,一是探索了关系编码器的不同架构,即Bert不同的输入和输出方式,并对其进行了对比评估;二是提出了Matching-the-blanks方法,能够在少量样本下使关系抽取的效果明显提升。
论文模型
基于最近deep transformer在语言表示建模方面的强大性能,这篇论文采用Bert作为主要工作的基准,并且探索了Transformer模型不同的关系表示方法。
Bert模型输入方式
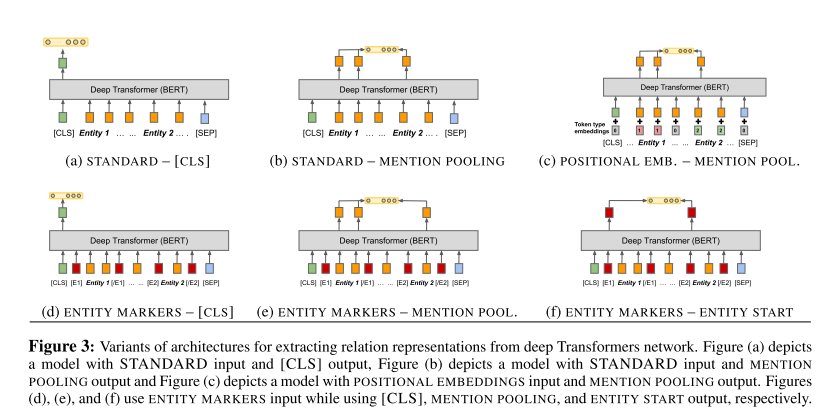
Bert模型的输入方式就是指如何在输入中给出两个实体(span)的位置信息,这里给出了三种方式。
- Standard input标准输入:在Bert的标准输入中,并没有给出两个实体的位置信息。
- Positional embeddings位置嵌入:Bert本身带有一个嵌入片段,主要是用来向模型中增加句子分段信息。但是这里为了解决标准输入缺失位置信息的问题,引入了两个新的嵌入片段,分别存储两个实体的位置信息。
- Entity marker tokens实体标记:在关系x中扩充了四个保留词片段,用来标记关系里两个实体的开始和结束位置。
Bert模型输出方式
Bert模型的输出方式是指如何从模型中得到一个固定长度的关系表示,这里也给出了三种方式。
- [CLS] token 【CLS】令牌:这种方式使用[CLS] token来作为模型输出的固定长度的关系表示。
- Entity mention pooling 实体池化:这种方式对两个实体使用MAXPOOL得到两个向量来代表两个实体,之后再将这两个向量进行拼接得到关系表示。
- Entity start state 实体开始位置:这种方式将两个实体开始位置的特殊标记进行拼接,得到关系表示。
Bert模型的不同变体
Bert模型的不同变体,即由不同的输入和输出方式组成的Bert模型结构,如图3(Figure 3)。经过在三个有监督的关系抽取任务和一个关系分类任务上的实验,结果显示使用Entity Markers实体标记作为输入方式和Entity Start实体开始位置作为输出方式得到的模型表现效果最好。
预训练方法Matching the Blanks
论文基于Harris的分布式假说,认为如果两个句子中包含相同的实体对,那么它们的关系表示应该尽可能相同,反之,如果两个句子中包含的实体对不相同,那么它们的关系相似度应该很低。这里计算关系相似度的方式是:假设两个句子的关系表示分别是r和s,那么使用内积
$$
r^T·s
$$
来表示两个关系的相似度。给出两个句子,经过上述Bert模型的变体,得到相应关系表示,按照论文的假设,模型只需要对句子中的实体对信息进行处理(即比较实体对是否相同),就可以最小化误差。因而论文提出了MTB(Matching the Blacks)方法。
为了避免实体对模型的学习干预过大,论文按照一定的概率(文中选择α=0.7)将句子中的实体替换为特殊标记[BLANK],使模型对句子中除实体外的文本信息进行建模,论文中使用采样策略从6亿对关系表示中来训练模型。
论文实验
论文使用Bert变体中表现最好的那个模型,即使用Entity Markers实体标记作为输入方式和Entity Start实体开始位置作为输出方式得到的Bert模型,来进行实验,并称之为BERT(EM)。经过实验,使用Matching the blanks进行预训练的Bert模型(BERT(EM)+MTB)要优于原来的Bert模型,并且在三个有监督的关系抽取任务中达到了SOTA结果。
经过在不同比例训练数据和不同数据集上的对比,结果显示使用MTB预训练的Bert模型能够使用较少的样本数据资源达到较好的效果,而且整体都优于原始的Bert模型。
论文总结
这篇论文提出了一种新的预训练方式MTB(matching the blanks),这种方式完全依赖于实体解析注释,能够在很少的样本数据情况下使模型达到较好的效果。另外这篇论文结合了微调的Bert变体模型,用来提取关系表示。实验显示,这篇论文的模型在三个关系提取的任务数据集中均达到了SOTA的结果,并且在few-shot关系匹配的任务上准确性超过了人类。
Emotion-Cause Pair Extraction: A New Task to Emotion Analysis in Texts
Xia, R., & Ding, Z. (2019). Emotion-Cause Pair Extraction: A New Task to Emotion Analysis in Texts. 1003–1012. https://doi.org/10.18653/v1/p19-1096
这篇论文提出了情感分析领域的一个新任务,即原因情感联合提取。之前的情感分析任务都是将情感提取和原因提取分开进行,而这篇论文的作者发现这两个任务并不是相互独立的,而是互相补充的。因而作者就这个想法提出了一个新的任务,将原因和情感联合提取,即Emotion-Cause Pair Extraction(ECPE)。同时,作者也提出了一种解决这个任务的方法,这个方法分为两步,第一步是通过多任务学习分别进行情感提取和原因提取,之后第二步将上一步提取出的情感和原因进行配对和筛选。这种方法经过在情感原因提取的语料上进行实验,表明了ECPE任务的可行性以及这种解决方法的高效性。
论文背景
情感原因提取任务(Emotion Cause Extraction,ECE)主要目的是从已标注情感的文本中提取出对应情绪的潜在原因。这项任务有两个缺点,第一就是在测试集上进行原因提取之前必须先标注文本的情感,这样使得ECE很难直接在实际应用中使用;第二就是这种先标注情感再提取原因的方法忽略了情感和原因之间的相互依赖性。
基于以上的背景以及ECE任务的两个缺陷,这篇论文提出了一个新的任务,情感原因联合提取(Emotion-Cause Pair Extraction, ECPE),这个任务的主要目的是联合提取出文档中所有潜在的情感和相应的原因组合。这个任务和ECE相比,并不需要标注文本中的情感,而且输出的结果是情感和相应原因的组合。
为了解决这个新提出的任务,这篇论文提出了一种分为两步的方法。第一步是通过两类多任务学习网络进行的两个独立子任务,分别进行情感提取和原因提取;第二步是对第一步得到的情感和原因进行配对和筛选。
这篇论文基于ECE基准语料构建了一个适合ECPE的语料,并且这篇论文在ECE基准数据集上对这种方法进行了评估,此外还对两个独立的子任务(情感提取和原因提取)进行了测试和评估。结果显示这篇论文的方法在不依赖情感标注测试集的情况下能够和目前较好的ECE方法媲美。
论文模型
论文模型分为两个步骤,分别是第一步独立的情感和原因提取和第二步情感原因配对和筛选。第一步使用了两个多任务学习网络,分别是独立多任务学习网络和交互多任务学习网络。第二步则是使用笛卡尔积来对情感和原因进行配对,并使用一个逻辑回归模型来判断情感原因对是否有效。
第一步:分别进行情感提取和原因提取
这一步采用了两个多任务学习网络:独立多任务学习网络和交互多任务学习网络。
独立多任务学习网络
这个学习网络采用了一个多层的双向LSTM,这个网络包含两层。低层包含一组单词级别的双向LSTM模型,每一个模型对应一个句子,整个模型将每个单词聚合成整个句子的信息,其中在获取句子表示信息的过程中采用了注意力机制。而高层则由两部分组成,一个对应情感提取,另一个对应原因提取,其中每一部分都是一个句子级别的双向LSTM,接收低层输出的句子表示,分别输出每个句子的情感预测和原因预测。网络结构如图2。
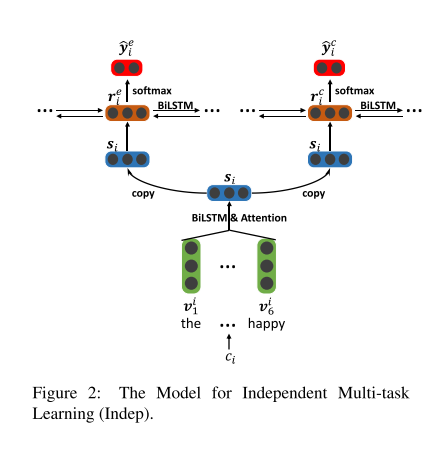
交互多任务学习网络
这个一个网络是上一个网络的增强版本,目的是为了获取情感和原因的联系。网络结构如图3。其中使用情感提取来增强原因提取的方法称为Inter-EC,使用原因提取来增强情感提取的方法称为Inter-CE。
和上一个网络相比,这个交互多任务网络的低层没有变化,而高层有所不同,尽管这个网络的高层也是有两部分组成,但是这两部分是有关联的,并不是分离的。其中第一部分输入独立的句子表示s,输出一个预测向量Y,包含了对应句子的预测结果;第二部分输入句子表示和相应预测向量的串联结果,输出最终的预测分布y。
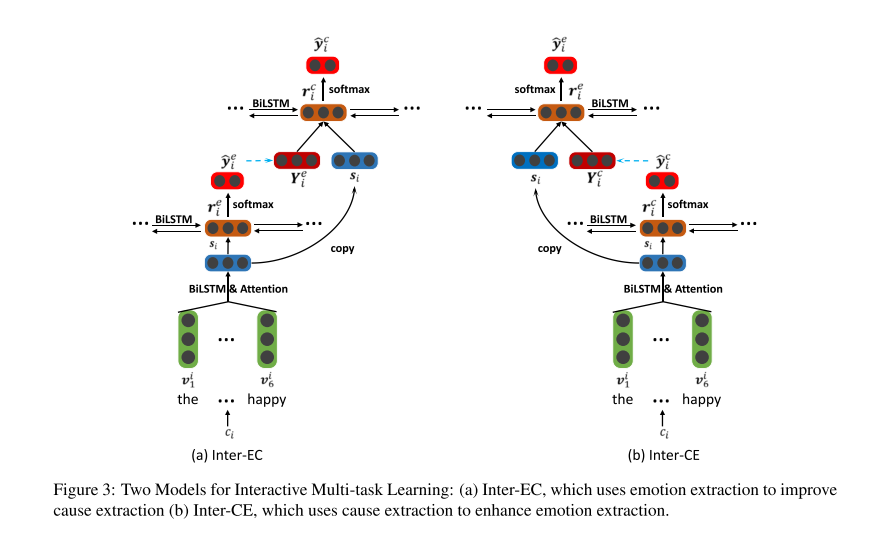
第二步:情感原因配对和筛选
这一步采用上一步得到的结果,一组情感句子和一组原因句子,目标是对这两组句子进行配对和筛选,得到一组合理的原因情感对。首先论文使用笛卡尔积得到了所有可能的配对结果,然后论文对这些可能的结果采用了一个逻辑回归模型进行筛选,得到了相对合理的原因情感对。
论文实验
这篇论文基于一个基准的ECE语料构建了一个ECPE语料,这个语料中每一个文档只包含一种情感和相应的一个或多个原因,并且对每个文档中的情感和相应的原因进行了标注。论文在训练模型过程中随机从语料中选择了90%的训练数据和10%的测试数据,为了保证结果的可靠性,论文重复实验了20次得到了最后的平均结果。至于模型评估标准方面,论文采用了准确率P,召回率R,以及F1值。论文对模型的两个步骤分别进行了测试,分别对Indep, Inter-CE, Inter-EC进行了测试。同时对Inter-CE和Inter-EC的上界进行了测试,也测试了情感原因对筛选环节对结果的影响。
在模型评估部分,论文将Inter-EC模型和现有的一些ECE方法进行了对比,结果如表5,其中Inter-EC模型并没有使用情感标注的测试集,而是采用未进行情感标注的测试集。结果显示,论文中提及的方法能够和目前一些较好的ECE方法媲美。论文还将ECE方法中表现较好的CANN(co-attention neural network)方法在未进行情感标注的测试集上进行实验,得到的结果效果不是很好,说明了本文提出的方法Inter-EC在未标注的测试集上有较好的表现结果。
论文总结
这篇论文提出了一个新的情感分析方面的任务——情感原因联合提取,主要是联合提取出文档中的情感和相应原因的组合。论文还提出了一种解决这个任务的方法,这个方法分两步,第一步利用多任务学习分别提取出文档中的情感和原因;第二步使用笛卡尔积对提取出的原因和任务进行配对,并采用一个筛选器对配对结果进行筛选。此外,基于现有的基准ECE语料,这篇论文构建了一个适合ECPE任务的语料。总的来讲,这篇论文提出了ECPE,并给出了一种解决方案,但这个解决方案还是存在部分问题,比如方法不太直接,以及第一步的错误会影响第二步的结果,所以未来这个方法还是需要进行改进,尽量能够一步完成。
Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification
Zhou, P., Shi, W., Tian, J., Qi, Z., Li, B., Hao, H., & Xu, B. (2016). Attention-based bidirectional long short-term memory networks for relation classification. 54th Annual Meeting of the Association for Computational Linguistics, ACL 2016 - Short Papers, 207–212. Retrieved from https://www.aclweb.org/anthology/P16-2034
这篇论文提出了一个基于注意力机制的双向LSTM网络(Att-BLSTM),目的在于更好地提取句子中重要的语义信息,其中主要是用于关系分类。另外这篇论文提出的这个模型不需要使用任何来自词汇资源或者NLP系统的特征信息,而是采用了一种相对简单的特征信息,将四个位置索引看作单独的词,然后将所有单词转换成词向量,生成一个简单但是完备的模型。论文对模型在SemEval数据集上进行评估,结果显示F1值达到84.0%,比现有的相关方法还要高。
论文背景
关系分类是NLP中一项重要的语义处理任务,目前比较好的方法依旧依赖于词汇资源比如WordNet或者NLP系统比如依赖解析和命名实体识别,以此来获取更高水平的特征。另外在关系分类中的一个挑战是重要的语义信息可能出现在句子的任何位置,这使得获取语义信息更加难了。为了解决这些困难,这篇论文提出了一个基于注意力机制的双向LSTM网络,从句子中获取重要的语义信息。
关系分类在早些时候使用的是基于模式识别的方法,并且使用额外的NLP系统来产生词汇特征,其中有一项相关工作就是将一些从外部语料中得到的特征用于SVM分类器,以此来获取更多语义信息。后来深度神经网络因为能够自动化的学习特征信息,便被用于语义获取。其中主要的有使用CNN进行关系分类和使用RNN进行长距离语义信息提取,另外相关变体还有双向RNN,SDP-LSTM和双向LSTM。
以往的一些神经网络模型,除了使用模型本身,还以来了外部的NLP工具和词汇资源,因而使用的特征信息较为复杂。这篇论文则采用了一种相对简单的方式,使用四个位置索引来标识一个单词,然后把所有单词转化成词向量,生成一个简单且完备的模型。
论文模型
这篇论文提出的Att-BLSTM模型总共有五个组件,分别是输入层,嵌入层,LSTM层,注意力层和输出层。每层的功能如下:
- 输入层:向模型中输入句子
- 嵌入层:将每一个单词映射到一个低维向量中
- LSTM层:采用双向LSTM来从上一层的结果中获取更高级别的特征信息
- 注意力层:这一层产生一个权重向量,然后通过和权重向量相乘,将从每一个时间步中得到的单词级别的特征聚合成一个句子级别的特征向量。
- 输出层:句子级别的特征向量最终被用于关系分类。
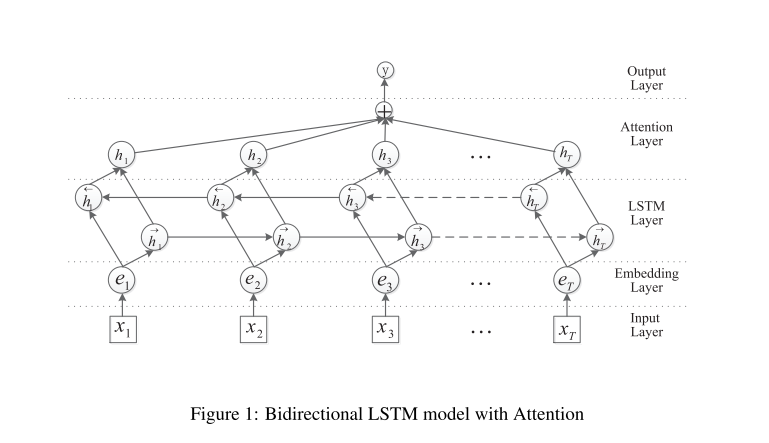
此外,模型在嵌入层、LSTM层和注意力层均采用了Dropout,并且还是用了L2范式进行约束,以此来防止过拟合。
论文实验
论文在SemEval-2010 Task 8 数据集上进行了实验,这个数据集包含9个双向关系和一个无向的其他关系类。数据集中总共有10717个样例,包含8000个训练句子和2717个测试句子。论文采用了官方评估标准对模型进行了评估,即对9个实际关系(除了其他关系类)采用了宏平均的F1值,并且考虑了方向性。
论文实验将论文中的Att-BLSTM模型和其他一些表现较好的关系分类方法进行对比。结果显示,这篇论文的方法Att-BLSTM得到了一个84.0%的F1值,在没有使用词汇资源和NLP系统的辅助下,比其他现有的一些方法表现都好。
论文总结
总的来说,这篇论文提出了一个新的神经网络模型,即Att-BLSTM,是一个用于关系分类的注意力双向LSTM模型。这个模型没有依赖NL工具,也没有使用词汇资源,它使用带有位置信息的原始文本作为输入。而模型经过在SemEval-2010关系分类任务上进行评估,有很好的表现,优于现有的模型。
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
Lan, Z., Chen, M., Goodman, S., Gimpel, K., Sharma, P., & Soricut, R. (2019). ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. 1–16. Retrieved from http://arxiv.org/abs/1909.11942
在预训练自然语言表示的任务中,虽然随着模型大小的逐渐增加,模型的效果会逐渐改善,但是模型的训练会受到GPU/TPU内存的限制,会耗费更长的训练时间,也可能会产生预料之外的模型效果变差。为了解决这些问题,这篇论文提出了两种减少模型参数的方法,并用于Bert模型上,以此来减少模型的内存消耗并且增加模型的训练速度。此外论文还使用了一个自我监督的损失函数,来关注句子之间的关联性。论文将这些改进方法使用在了Bert模型上,并提出了一个新的是用更少参数的模型ALBERT,并且对新提出的这个模型进行了评估和测验,结果显示这个这个模型能够在GLUE,RACE和SQuAD这些基准数据集上达到SOTA的结果。
论文背景
这篇论文针对目前模型大小逐渐增加产生的一些内存耗费过多和训练时间过长等一些问题,基于Bert模型提出了相应的解决方案。具体来说,就是设计了一个新的模型,一个轻量级的Bert,简称ALBERT。ALBERT和Bert相比,有三个改进的地方,分别是两种减少参数的技术和一个针对句子顺序预测的自监督损失函数。其中两种减少参数的技术分别是因式分解向量参数和不同层参数共享。因式分解向量参数就是将较大的词汇向量矩阵分解成两个小的矩阵,将隐藏层的大小和词汇向量大小分开。这种分离可以单独增加隐藏层大小而不会影响词汇向量的参数大小。而采用不同层参数共享,可以阻止参数量随着模型深度增加而增多。另外的一种改进,是一个针对句子顺序预测的自监督的损失函数,被称为SOP。SOP的提出主要是为了关注句子之间的联系,同时解决原始Bert模型中下一个句子预测损失函数(NOP)产生的低效性。这篇论文对模型在一些基准数据集上进行评估和测试,结果显示模型能够在GLUE,RACE和SQuAD这些基准数据集上达到SOTA的结果。
论文模型
ALBERT模型是基于BERT的架构,大部分与之相同,都是使用transformer encoder堆叠而成。这里主要给出了ALBERT在Bert基础上给出的三个改进,因式分解向量参数,不同层参数共享和针对句子顺序预测的自监督损失函数SOP。
因式分解向量参数:在Bert模型和一些变体模型中,都将单词向量大小E和隐藏层大小H设为一样,即E=H。这样的设置会导致模型虽然有众多参数,但是真正训练时并不能充分利用这些参数。因为这篇文章设置隐藏层大小H远大于单词向量大小E。并且使用饮食分解的方法,将向量参数从V x H分解为V x E+E x H。这样相比之前就有效地减少了参数数量,论文还对E值的不同取值进行了实验,结果显示E值取为128效果比较良好。
不同层参数共享:参数共享的方法可以分为三类,分别是只共享前馈神经网络参数(FFN),只共享注意力参数,二者都共享即共享所有参数。这篇论文中的模型使用的方法是共享所有参数,并且论文还对这三种方法进行了实验对比,结果显示共享所有参数在参数减少方面表现效果较好。这种参数共享的策略能够很好地减少参数数量,而且实验结果相比之前也没有太大变化,依旧比较良好。
SOP损失函数:这篇论文认为对句子之间的联系进行建模是对语言理解比较重要的一个方面,因而针对ALBERT,论文使用了一个句子顺序预测损失函数(SOP),没有对主题进行预测,而是聚焦于对句子之间的联系。这个SOP损失函数使用和BERT类似的正向例子,即从同一个文档中获取到的两个连续的句子,而使用了和Bert不一样的反例,Bert使用了来自不同文档的两个片段,ALBERT使用了同一个文档中两个顺序交换的连续的句子。另外,对比原始Bert中的NSP和ALBERT中的SOP,可以得到,NSP损失函数不能解决SOP的任务,但是SOP损失函数能够解决NSP的任务,而且通过实验显示,SOP在下游任务的表现优于NSP。
论文实验
这篇论文对ALBERT模型和BERT模型进行了整体对比试验,也针对ALBERT模型的三个改进之处分别进行了对照实验,同时也对训练时间、模型深度和宽度以及dropout层对模型的影响进行了探讨。经过和Bert模型的对比,ALBERT减少了70%的参数连个,另外ALBERT-xxlarge(H=4096,12-layer)的F1值在多个数据集上均优于Bert-large(H=1024,24-layer),结果分别为SQuAD v1.1 (+1.7%), SQuAD v2.0 (+4.2%), MNLI (+2.2%),SST-2 (+3.0%),and RACE (+8.5%)。
论文总结
总的来说,论文提出的ALBERT-xxlarge模型和Bert-large模型相比,在减少了参数量的同时还能得到更好的结果,不过优于模型较大的结构,它的计算复杂度还是很高的,依旧需要很大的计算量,所以论文的下一步计划使用稀疏注意力机制和分块注意力机制来加快模型训练的速度。同时,论文还指出尽管句子顺序预测是在自然语言表示学习方面是一个有效的任务,但论文猜想在目前自监督训练损失函数方面还有很多维度信息可以继续去挖掘,这些信息可能对最终的结果表示有很大影响。
Attention is all you need
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … Polosukhin, I. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 2017-Decem(Nips), 5999–6009. Retrieved from https://arxiv.org/pdf/1706.03762.pdf
这篇论文提出了一个新的模型Transformer,这个模型是针对机器翻译的任务提出的。在此之前,机器翻译的任务主要主要是采用RNN神经网络,RNN可以处理任意长度的输入,并且能够提取序列的时序信息,不过RNN也有一些不足,主要缺点有两个,一个是RNN序列处理难以并行化,当数据量大的时候训练时间资源耗费较多;另一个是RNN网络比较难以处理长距离和层级化的依赖关系,这样不太利于处理长文本,也导致机器翻译任务的精度有所下降。
因而,针对上述RNN网络存在的问题,谷歌在这篇文章中提出了自己的解决方案,即Tranformer模型。这个模型是一个Seq2Seq模型,并且采用了注意力机制。模型整体架构是由Encoder和Decoder两部分组成,其中Encoder和Decoder分别有6层,Encoder的最后一层与Decoder的每一层进行连接,并进行注意力操作。论文对模型在机器翻译任务上进行了评估,结果显示,模型在WMT2014 English-to-German和English-to-French任务上均达到了新的SOTA结果。
论文背景
在机器翻译方面,主要采用的是RNN网络模型,但是RNN本身有两个缺点,一是RNN进行序列处理时难以进行并行化,另一个是RNN网络难以处理长距离和层级化的依赖关系。因而这篇论文就这个问题的解决,针对机器翻译任务,提出了一个新的模型,即Transformer模型。
这个模型采用了注意力机制,由encoder和decoder堆叠而成。这个模型允许并行化,并且经过论文在机器翻译任务上的测试,结果显示该模型达到SOTA结果。
论文模型
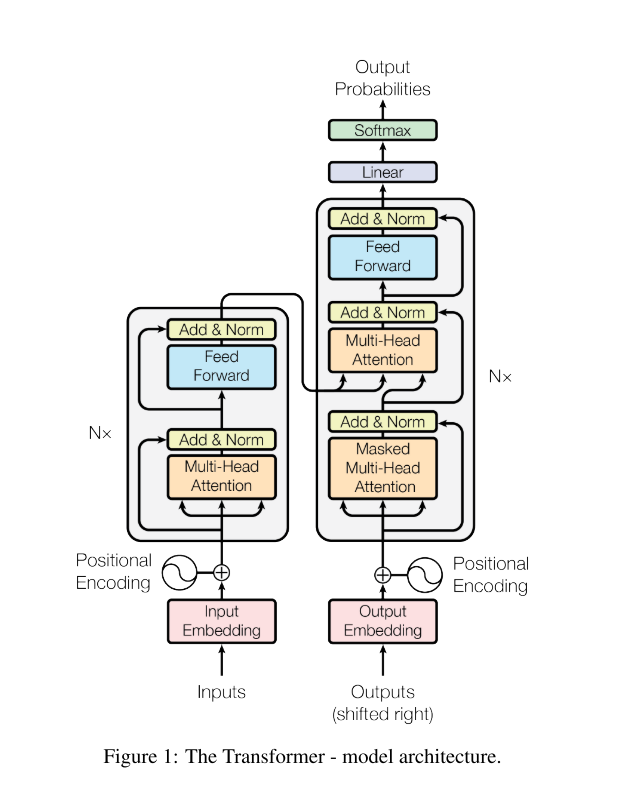
Transformer 遵循上图1的总体架构,采用了encoder和decoder的堆叠,并且在模型中使用了自我注意力机制和多头注意力机制,它把注意力机制当作一个基于内容的查询的过程,设置三个向量:查询向量Q,key向量K,value向量V,每一个向量都是通过它的输入向量和权重矩阵相乘得到的,使用这三个向量进行计算,最终得到注意力score。
这个架构中由六层encoder和decoder组成。encoder中每一层有两个子层,第一个是一个多头的自我注意机制,第二个是一个简单的全连接的前馈网络,另外在每一个子层周围进行连接并进行层标准化。
类似的,decoder也有两个和encoder一样的子层,不过除每个编码器层中的两个子层外,decoder还插入第三个子层,该子层对encoder堆栈的输出结果执行多头注意机制。
这个模型中,注意力机制是神经网络隐层之间的一种相似度表示,自我注意力机制是表示句子内部词和词之间的关联关系,多头注意力机制是对注意力机制的完善,具体来说就是,将三个向量Q、K、V通过参数矩阵进行映射,之后做Attention,将这个过程重复h次,并拼接其结果。
在Transformer架构中,有三个地方使用自我注意机制。第一,在“编解码器注意”层中,查询来自于前一解码器层,存储键值来自于编码器的输出。第二,编码器包含自我注意层。在一个self-attention层中,所有的键值和查询都来自同一个位置,在本例中,这个位置是编码器中上一层的输出。第三,解码器中的自我注意层允许解码器中的每个位置关注解码器中之前层的所有位置。
论文实验
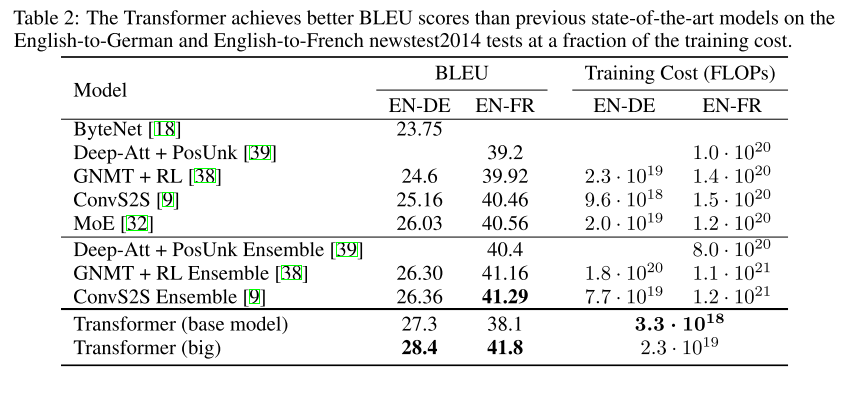
论文对Transformer模型在机器翻译任务上进行了评估,在2014年WMT英德翻译任务中,big transformer model(见表2中的transformer (big))的性能比之前报道的最佳模型(包括集成电路)高出2.0 BLEU以上,达到了一个新的SOTA的BLEU评分28.4,在英法翻译任务上也达到了一个新的SOTA的BLEU评分41.8。此外,为了评估transformer 不同组件的重要性,这篇论文以不同的方式改变了基本模型,在开发集newstest2013上测量了英语到德语翻译的性能变化。
论文总结
这篇论文提出了一个Transformer模型,这是一个基于注意机制的序列转换模型,在编码器和解码器架构中使用多头自注意机制,并且最终在机器翻译这方面的评估也能得到一个很好的效果。此外,这个模型的潜能较大,可拓展性较强,之后在各种NLP任务上表现优秀的Bert模型的基础就是本文中提出的Transformer模型。
An Introductory Survey on Attention Mechanisms in NLP Problems
Hu, D. (2020). An Introductory Survey on Attention Mechanisms in NLP Problems. 432–448. https://doi.org/10.1007/978-3-030-29513-4_31
这篇论文介绍了注意力机制以及相关变体,通过对近些年一些工作的调研,总结了注意力机制在不同的NLP任务中的使用,评估了相应性能,探索了注意力机制与机器学习方法的关联。这篇论文首先介绍了注意力机制的基本形式,然后介绍了几种不同的注意力机制的变体,分别是多维度注意力机制,分层注意力机制,自注意力机制,基于内存的注意力机制和特定任务的注意力机制。之后论文给出了注意力机制在机器学习方面的一些应用,比如预训练和聚集。最后论文并对两种评价注意力机制的性能的方法(定性和定量)进行了描述。
论文背景
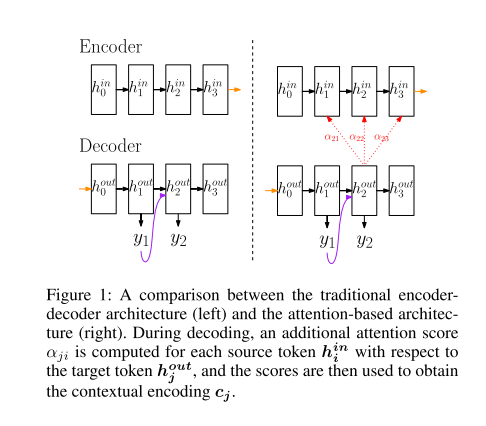
论文从机器翻译任务入手,引出了基本的注意力机制。传统的机器翻译多是基于RNN架构,但这种架构有两个缺点,一个是RNN具有遗忘性,即随着时间前向传播的过程中,RNN会遗弃一些旧的信息;另一个缺点是在解码过程中没有明确的单词划分,所以在经过整个句子序列时注意力会被分散。为了解决这个问题,注意力机制被提出。和传统的编码解码结构相比,基于注意力机制的结构在解码过程中产生下一个隐藏状态时,除了依赖前一个隐藏状态和预测出的单词外,还依赖隐藏状态的加权和。
除了基本的注意力机制外,论文还总结了几种注意力机制的变体,分别是多维度注意力机制,分层注意力机制,自注意力机制,基于内存的注意力机制和特定任务的注意力机制。
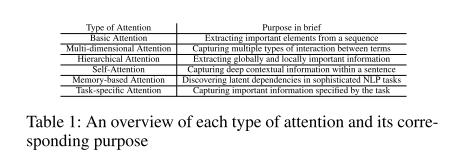
注意力机制的变体
这篇论文中提到了五种注意力机制的变体,分别是多维度注意力机制,分层注意力机制,自注意力机制,基于内存的注意力机制和特定任务的注意力机制。
多维度注意力机制(multi-dimensional Attention)
多维度注意力机制用于获取不同表示空间中的术语之间的交互。这种多维方法的缺点是,强指示性元素可以同时吸引多种类型的注意力,因而降低了其表示能力。
分层注意力机制(Hierarchical Attention)
分层注意力机制将文本考虑为层层嵌套的结构,比如字符 ->单词 ->句子->文档,分层注意力机制或采用自顶向下或采用自底向上的方式来从全局和局部识别文章的细节和重要信息。
自注意力机制(Self-Attention)
自注意力机制将句子中每一个词和句子内部的其他词进行相似度匹配,得到注意力机制,目的在于获取句子内部各个词语之间的依赖关系。这中注意力机制的变体在transformer中有具体应用。
基于内存的注意力机制(Memory-based Attention)
基于内存的注意力机制将注意力分数的计算过程重新解释为根据查询进行内存寻址的过程,将编码视为从基于注意力分值的存储中查询注意力分支的过程。在重用性方面,这种注意力机制能够通过迭代内存更新来模拟时间推理过程,逐步将注意力引导到正确的答案位置,对于答案和问题没有直接关系的复杂问答效果较好。在灵活性方面,这种注意力机制可以人工设计key embedding来更好的匹配问题,可以人工设计value embedding来更好的匹配答案。这种分开设计,能够分段地注入领域知识,使模块之间的通信更有效,并将模型推广到除传统问答之外的更广泛的任务。
特定任务注意力机制(Task-specific Attention)
特定任务注意力机制的泛化能力不是很好,但是,这种注意力机制针对具体任务进行设计和优化,因而在特定任务上效果较好。
应用及评估
这篇论文列举了注意力机制的三个应用,分别是ensemble,gating,pre-training。
ensemble
将序列中的每个元素看作单个模型,attention权重看作是这些模型的加权融合,那么attention机制就类似于模型融合。
gating
一种基于attention的GRU(门控制循环网络)是将更新门替换为attention权重。
pre-training
预训练的词向量在很多NLP任务上至关重要。传统的方法有Skipgram、Cbow、Glove等等,均是利用大规模语料基于上下文训练一个无监督模型,学习到每个词的高位分布式表示。与此不同的是,预训练方法集成了基于attention的深度网络架构,旨在学习到更高质量的单词表示,包含了上下文的句法语义信息,然后对模型微调以适应下层监督任务。比如BERT。
这篇论文从定量和定性的角度对注意力机制评估方式进行了描述。定量评估方式分为内在评估方法和外在评估方法。虽然内在评估方法可以精确地测量性能,但它们往往局限于特定的任务,严重依赖于标记数据的丰富性;外在评估方法使用更广泛,但从结果中很难评判是否提升的效果与注意力机制的运用有关。而定性的评估方式主要使用热力图,这也是目前使用最广泛的评估方式。
论文总结
最后,论文指出注意力机制在embedding预训练中的使用是比较有前景的方向,比如目前比较流行的Bert模型。