Attention is all you need
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … Polosukhin, I. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 2017-Decem(Nips), 5999–6009. Retrieved from https://arxiv.org/pdf/1706.03762.pdf
Introduction
Recurrent models typically factor computation along the symbol positions of the input and output sequences. Aligning the positions to steps in computation time, they generate a sequence of hidden states ht, as a function of the previous hidden state ht−1 and the input for position t. This inherently sequential nature precludes parallelization within training examples, which becomes critical at longer sequence lengths, as memory constraints limit batching across examples.
Attention mechanisms have become an integral part of compelling sequence modeling and transduction models in various tasks, allowing modeling of dependencies without regard to their distance in the input or output sequences
In this work we propose the Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output. The Transformer allows for significantly more parallelization and can reach a new state of the art in translation quality after being trained for as little as twelve hours on eight P100 GPUs.
递归模型通常沿着输入和输出序列的符号位置进行因子计算。这个固有的顺序排除了使用并行化的可能,而并行化在长序列的训练中非常关键,因为内存约束限制批处理。
在各种任务中,注意力机制已经成为引人注目的序列建模和转换模型的一个组成部分,允许对依赖项进行建模,而不考虑它们在输入或输出序列中的距离。然而,这种注意力机制经常与递归模型一起使用。
这篇论文提出了一种Transformer,这是一种模型架构,它没有采用递归模型,而是完全依赖一种注意力机制来生成输入和输出之间的全局依赖。这种Transformer允许并行化,并且经过训练之后能够在翻译质量方面达到一个新的高度。
Model Architecture
The Transformer follows this overall architecture using stacked self-attention and point-wise, fully connected layers for both the encoder and decoder, shown in the left and right halves of Figure 1, respectively.
The encoder is composed of a stack of N = 6 identical layers. Each layer has two sub-layers. The first is a multi-head self-attention mechanism, and the second is a simple, position- wise fully connected feed-forward network. We employ a residual connection [11] around each of the two sub-layers, followed by layer normalization.
The decoder is also composed of a stack of N = 6 identical layers. In addition to the two sub-layers in each encoder layer, the decoder inserts a third sub-layer, which performs multi-head attention over the output of the encoder stack.
An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The two most commonly used attention functions are additive attention , and dot-product (multiplicative) attention. Dot-product attention is identical to our algorithm. Additive attention computes the compatibility function using a feed-forward network with a single hidden layer. While the two are similar in theoretical complexity, dot-product attention is much faster and more space-efficient in practice, since it can be implemented using highly optimized matrix multiplication code.
In “encoder-decoder attention” layers, the queries come from the previous decoder layer, and the memory keys and values come from the output of the encoder.
The encoder contains self-attention layers. In a self-attention layer all of the keys, values and queries come from the same place, in this case, the output of the previous layer in the encoder. Each position in the encoder can attend to all positions in the previous layer of the encoder.
Similarly, self-attention layers in the decoder allow each position in the decoder to attend to all positions in the decoder up to and including that position.
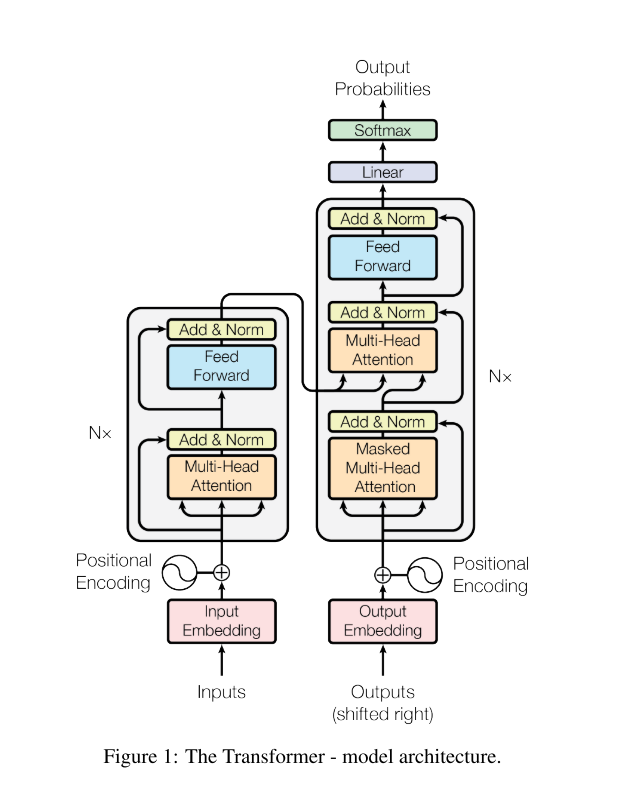
Transformer 遵循图一的总体架构,使用堆叠的自我注意机制,以及针对编码器和解码器的全连接层。
这个架构中的编码器是由N = 6个相同的层组成。每一层有两个子层,第一个是一个多头的自我注意机制,第二个是一个简单的全连接的前馈网络,另外在每一个子层周围使用一个剩余连接并进行层标准化。
类似的,解码器也由N = 6个相同的层组成。除每个编码器层中的两个子层外,解码器还插入第三个子层,该子层对编码器堆栈的输出执行多头注意。
注意函数可以说是将查询和一组键值对到输出的映射,其中查询、键、值和输出都是向量。两个最常用的注意函数是加法注意和点积(乘法)注意。点积注意与我们的算法相同。加性注意是利用带有单隐层的前馈网络计算兼容性函数。虽然这两种方法在理论上的复杂度相似,但由于点积可以使用高度优化的矩阵乘法代码来实现,因此点积注意在实践中更快、更节省空间。
这Transformer架构中,有三个地方使用自我注意机制。第一,在“编解码器注意”层中,查询来自于前一解码器层,存储键值来自于编码器的输出。第二,编码器包含自我注意层。在一个self-attention层中,所有的键值和查询都来自同一个位置,在本例中,这个位置是编码器中上一层的输出。第三,解码器中的自我注意层允许解码器中的每个位置关注解码器中之前层的所有位置。
Why Self-Attention
we compare various aspects of self-attention layers to the recurrent and convolutional layers. Motivating our use of self-attention we consider three desiderata. One is the total computational complexity per layer. Another is the amount of computation that can be parallelized, as measured by the minimum number of sequential operations required. The third is the path length between long-range dependencies in the network. As side benefit, self-attention could yield more interpretable models.

这篇论文在这一部分将自我注意层的各个方面与递归层和卷积层进行了比较。最终考虑到以下三个因素,选择了自我注意机制。一个是每层的总计算复杂度。另一个是可以并行化的计算量,由所需的最小顺序操作数来衡量。第三个是网络中远程依赖项之间的路径长度。另外,作为附带好处,自我注意机制可以产生更多可解释的模型。
Training and Results
On the WMT 2014 English-to-German translation task, the big transformer model (Transformer (big) in Table 2) outperforms the best previously reported models (including ensembles) by more than 2.0 BLEU, establishing a new state-of-the-art BLEU score of 28.4.
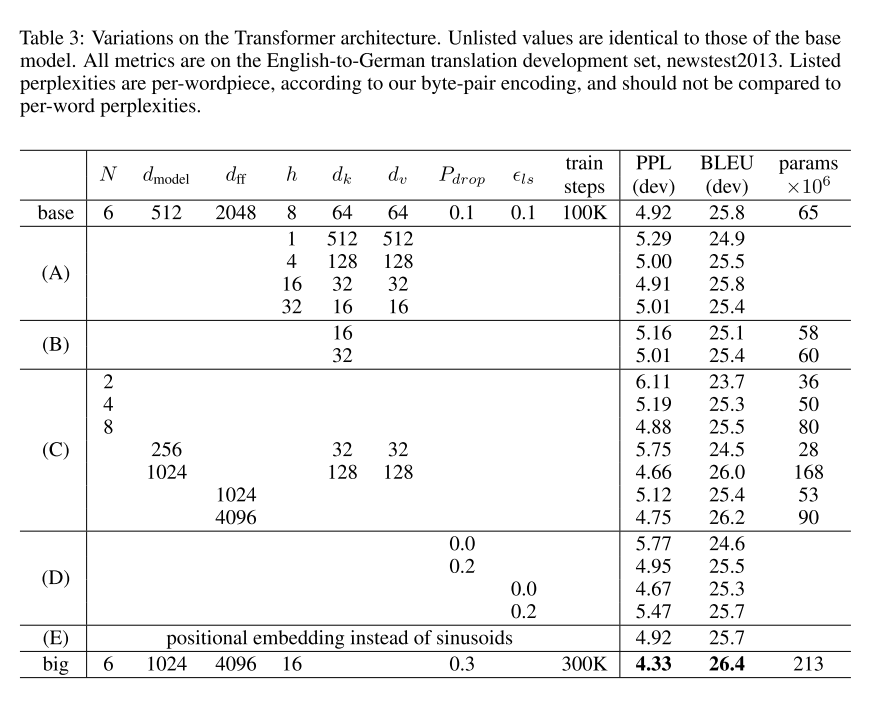
To evaluate the importance of different components of the Transformer, we varied our base model in different ways, measuring the change in performance on English-to-German translation on the development set, newstest2013.
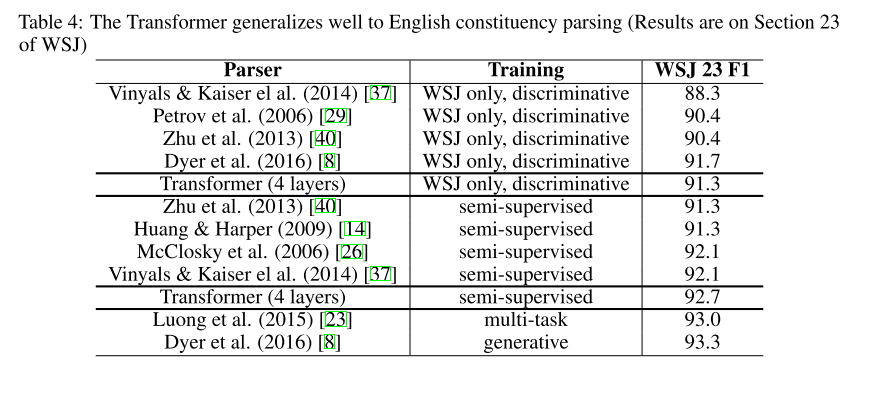
Our results in Table 4 show that despite the lack of task-specific tuning our model performs surprisingly well, yielding better results than all previously reported models with the exception of the Recurrent Neural Network Grammar [8].
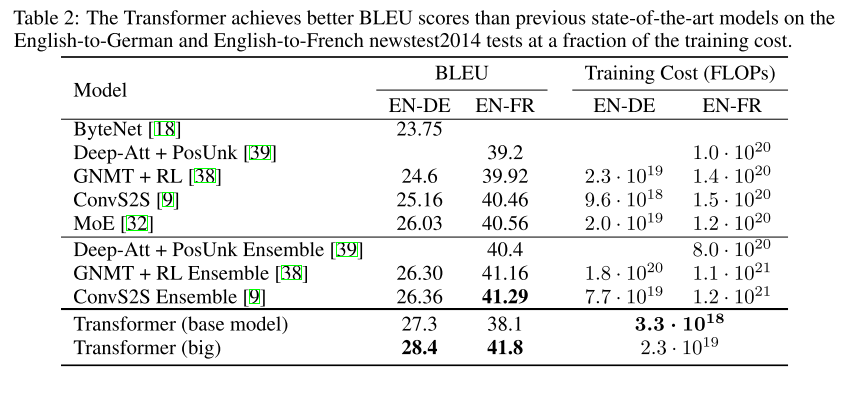
在2014年WMT英德翻译任务中,big transformer model(见表2中的transformer (big))的性能比之前报道的最佳模型(包括集成电路)高出2.0 BLEU以上,建立了一个新的最先进的BLEU评分28.4。
为了评估transformer 不同组件的重要性,这篇论文以不同的方式改变了基本模型,在开发集newstest2013上测量了英语到德语翻译的性能变化。
表4中的结果显示,尽管缺少特定于任务的调优,但是模型执行得出奇地好,除了递归神经网络语法之外,它比所有先前报告的模型都产生了更好的结果。
Conclusion
In this work, we presented the Transformer, the first sequence transduction model based entirely on attention, replacing the recurrent layers most commonly used in encoder-decoder architectures with multi-headed self-attention.
这篇论文提出了一个Transformer,这是第一个完全基于注意机制的序列转换模型,使用多头自注意机制取代了编码器和解码器架构中最常用的循环层,最终在机器翻译这方面也能得到一个更好的效果,并且还具有较好的拓展性,未来可能在其他任务上表现出优良性能。
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
Dai, Z., Yang, Z., Yang, Y., Carbonell, J., Le, Q. V., & Salakhutdinov, R. (2019). Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context. Retrieved from http://arxiv.org/abs/1901.02860
http://ai.googleblog.com/2019/01/transformer-xl-unleashing-potential-of.html
Introduction
We propose a novel neural architecture Transformer-XL that enables learning dependency beyond a fixed length with- out disrupting temporal coherence. Our main technical contributions include introducing the notion of recurrence in a purely self- attentive model and deriving a novel positional encoding scheme. These two techniques form a complete set of solutions, as any one of them alone does not address the issue of fixed-length contexts. Transformer-XL is the first self-attention model that achieves substantially better results than RNNs on both character-level and word-level language modeling.
长期依赖关系问题是序列模型中常见的现象,使用神经网络来解决长期依赖关系仍具有挑战性,例如基于Gating的RNN和梯度裁剪技术(gradient clipping)虽然具有一定的解决长期依赖关系的能力,但还不能完全解决这个问题,而Transformer可以很好的获取长期依赖关系,但是仅限于固定长度的上下文,即将一个长的文本序列截断为几百个字符的固定长度片段,然后分别处理每个片段。这就产生了两个关键的限制,依赖关系的长度受限以及上下文碎片化。
而这篇论文为了解决这些限制,提出了一个新的架构,Transformer-XL(meaning extra long),它能够使得依赖关系不受固定长度的限制,而且还有一些新的优势。Transformer-XL 主要有两种技术组成,一种是片段级递归机制(segment-level recurrence mechanism),另一种是相对位置编码方案(relative positional encoding scheme)
Model
To address the limitations of using a fixed-length context, we propose to introduce a recurrence mechanism to the Transformer architecture. During training, the hidden state sequence computed for the previous segment is fixed and cached to be reused as an extended context when the model processes the next new segment.
Besides achieving extra long context and resolving fragmentation, another benefit that comes with the recurrence scheme is significantly faster evaluation. Specifically, during evaluation, the representations from the previous segments can be reused instead of being computed from scratch as in the case of the vanilla model.
In order to avoid this failure mode, the fundamental idea is to only encode the relative positional information in the hidden states. Under the new parameterization, each term has an intuitive meaning: term (a) represents content- based addressing, term (b) captures a content- dependent positional bias, term (c) governs a global content bias, and (d) encodes a global positional bias.
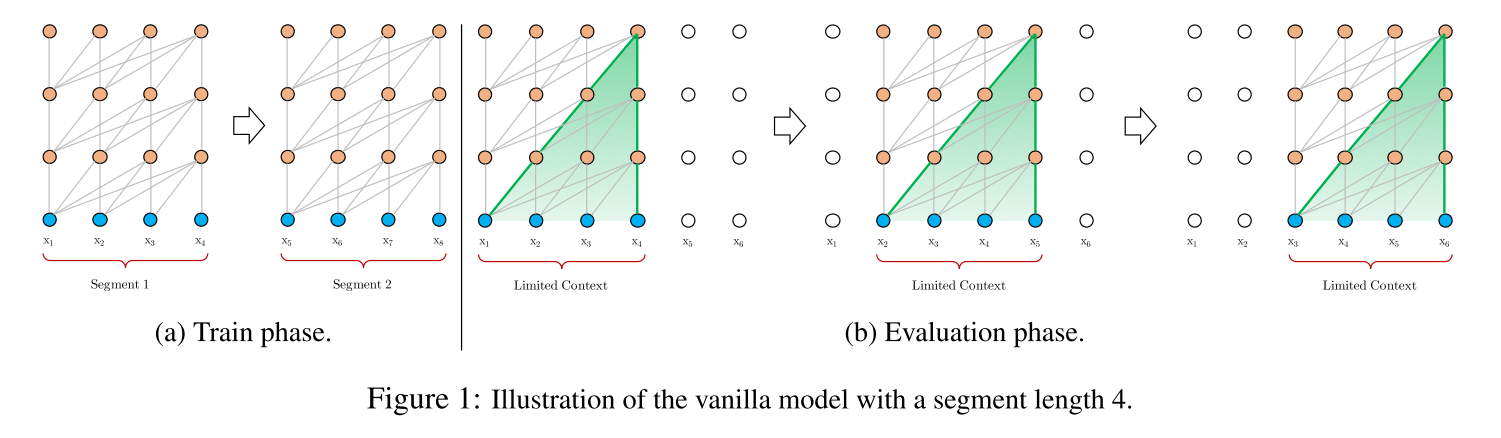
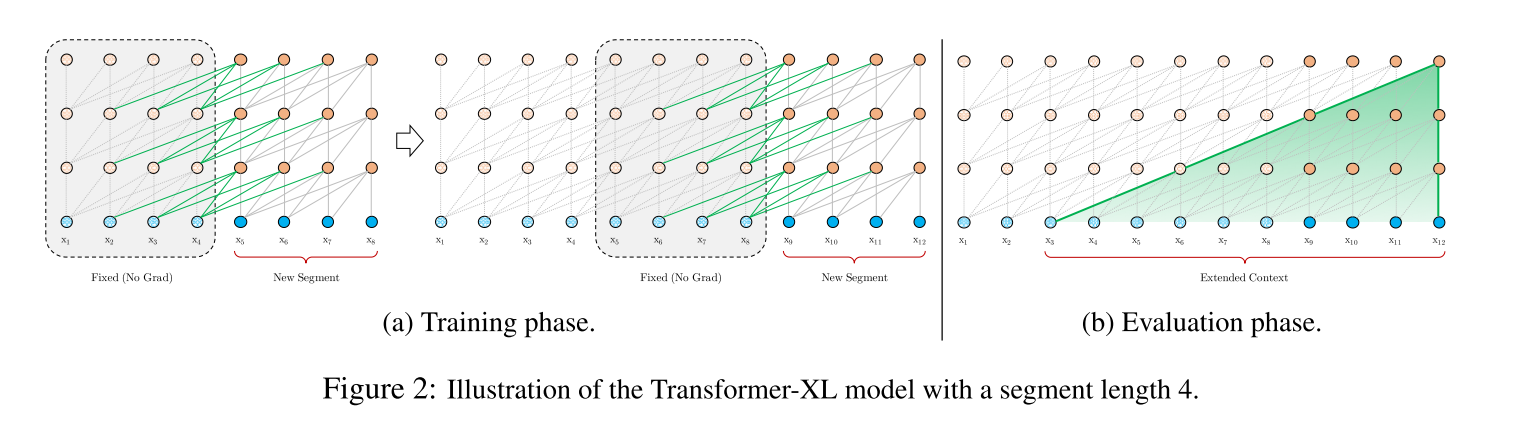
片段级递归机制: 训练过程中,对前一个分段计算的表示进行修复并缓存,以便在模型处理下一个新的分段时作为扩展上下文重新利用。这种额外的连接将最大可能依赖关系长度增加了N倍,其中N表示网络的深度,因为上下文信息现在可以跨片段边界流动。此外,这种递归机制还解决了上下文碎片问题,为新段前面的token提供了必要的上下文。
然而,单纯应用片段级递归机制是不行的,因为当重用前面的段时,位置编码是不一致的。因此,这篇论文提出了一种新的相对位置编码方案,使递归机制成为可能。
Experiments
We apply Transformer-XL to a variety of datasets on both word-level and character-level language modeling to have a comparison with state-of-the- art systems, includingWikiText-103 (Merity et al., 2016), enwik8 (LLC, 2009), text8 (LLC, 2009), One Billion Word (Chelba et al., 2013), and Penn Treebank (Mikolov and Zweig, 2012).
We conduct two sets of ablation studies to examine the effects of two proposed techniques used in Transformer-XL: the recurrence mechanism and the new positional encoding scheme.
Trained only on WikiText-103 which is medium- sized, Transformer-XL is already able to generate relatively coherent articles with thousands of to- kens without manual cherry picking, despite minor flaws.
Finally, we compare the evaluation speed of our model with the vanilla Transformer model (Al- Rfou et al., 2018). As shown in Table 9, due to the state reuse scheme, Transformer-XL achieves an up to 1,874 times speedup during evaluation.
Transformer-XL在各种主要的语言建模(LM)基准测试中获得新的最优(SoTA)结果,包括长序列和短序列上的字符级和单词级任务。实验证明, Transformer-XL 有三个优势:
Transformer-XL学习的依赖关系比RNN长约80%,比vanilla Transformers模型长450%。(尽管后者在性能上比RNN好,但由于固定长度上下文的限制,对于建模长期依赖关系并不是最好的。)
因为不需要重复计算,Transformer-XL在语言建模任务的评估期间比vanilla Transformer快1800+倍。
因为建模长期依赖关系的能力,Transformer-XL在长序列上具有更好的Perplexity, 预测样本方面更准确,并且通过解决上下文碎片化问题,在短序列上也具有更好的性能。
Conclusions
Transformer-XL obtains strong perplexity results, models longer-term dependency than RNNs and Transformer, achieves substantial speedup during evaluation, and is able to generate coherent text articles.
Transformer XL比RNN和Transformer具有较强的perplexity,对长期依赖关系进行建模,在评估过程中实现了实质性的加速,能够生成连贯的文本文章。
Neural Machine Translation by Jointly Learning to Align and Translate
Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural Machine Translation by Jointly Learning to Align and Translate. Retrieved from http://arxiv.org/abs/1409.0473
Introduction
In this paper, we conjecture that the use of a fixed-length vector is a bottleneck in improving the performance of this basic encoder–decoder architecture, and propose to extend this by allowing a model to automatically (soft-)search for parts of a source sentence that are relevant to predicting a target word, without having to form these parts as a hard segment explicitly.
The improvement is more apparent with longer sentences, but can be observed with sentences of any length. On the task of English-to-French translation, the proposed approach achieves, with a single model, a translation performance comparable, or close, to the conventional phrase-based system. Furthermore, qualitative analysis reveals that the proposed model finds a linguistically plausible (soft-)alignment between a source sentence and the corresponding target sentence.
这篇论文发现使用固定长度的向量阻碍了基本编码解码架构性能的提升,并拓展了这种方法,允许一个模型自动搜索和预测目标词相关的部分,并不是明确地形成这些部分。这种改进在长句中表现更为明显,但任何长度的句子都有改善。在英法翻译任务中,该方法通过单一的模型实现了与传统的基于短语的翻译系统相当或接近的翻译性能。此外,该模型在源句和对应的目标句之间找到了一种语言上合理的(软)对齐。
Background: Neural Machine Translation
Two recurrent neural networks (RNN) were used by (Cho et al., 2014a) and (Sutskever et al., 2014) to encode a variable-length source sentence into a fixed-length vector and to decode the vector into a variable-length target sentence.
Neural machine translation systems have surpassed the performance of existing translation systems, when used as a part of the existing system, for instance, to score the phrase pairs in the phrase table (Cho et al., 2014a) or to re-rank candidate translations.
论文在这一部分介绍了一些之前的神经机器翻译的方法,其中一种方法是利用两个递归神经网络(RNN)将一个变长源句编码为一个定长向量,并将该向量解码为一个变长目标句。神经机器翻译系统已经超越了现有翻译系统的性能。
Learning to Align and Translate
We propose a novel architecture for neural machine translation. The new architecture consists of a bidirectional RNN as an encoder and a decoder that emulates searching through a source sentence during decoding a translation.
By letting the decoder have an attention mechanism, we relieve the encoder from the burden of having to encode all information in the source sentence into a fixed- length vector.
We would like the annotation of each word to summarize not only the preceding words, but also the following words. Hence, we propose to use a bidirectional RNN , which has been successfully used recently in speech recognition.
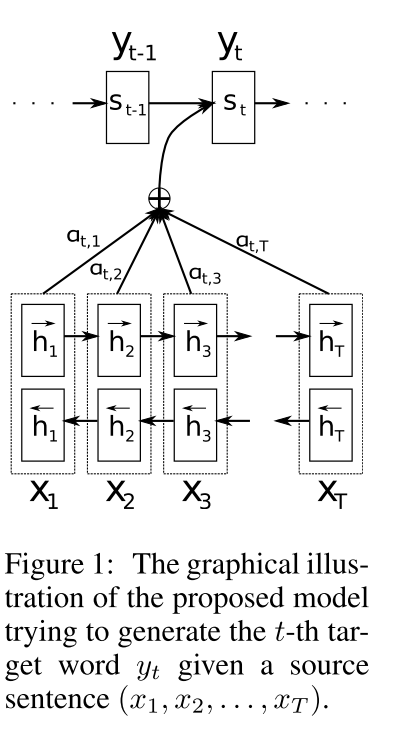
这篇论文提出了一种新的神经机器翻译体系结构。该结构由双向RNN作为编码器和解码器组成,解码器在解码过程中模拟对源语句的搜索。通过让解码器有一个注意机制,使得编码器不必将源语句中的所有信息编码为固定长。因为每个单词的注释不仅要总结前面的单词,还要总结下面的单词。因此,这篇提出了一种双向RNN,这种结构已经成功地应用于语音识别。
Experiment and Results
We evaluate the proposed approach on the task of English-to-French translation. We use the bilingual, parallel corpora provided by ACL WMT ’14.4 As a comparison, we also report the performance of an RNN Encoder–Decoder which was proposed recently by Cho et al. (2014a). We use the same training procedures and the same dataset for both models.
In Table 1, we list the translation performances measured in BLEU score. It is clear from the table that in all the cases, the proposed RNNsearch outperforms the conventional RNNenc. More importantly, the performance of the RNNsearch is as high as that of the conventional phrase-based translation system (Moses), when only the sentences consisting of known words are considered.
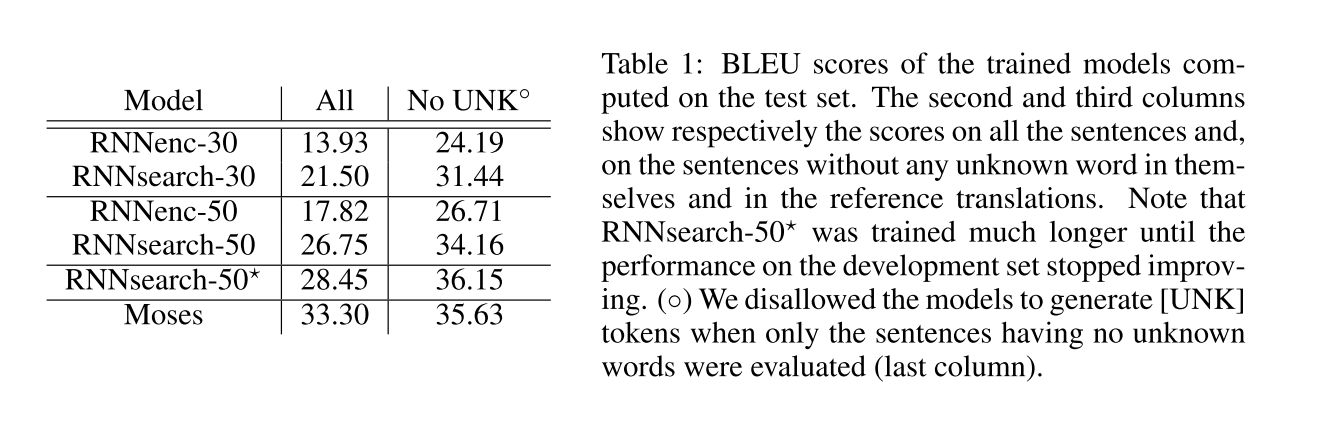
这篇论文对所提出的方法进行了实验,使用ACL WMT’14.4提供的双语并行语料库作为比较,并对比了Cho等人(2014a)最近提出的RNN编解码器的性能。其中对这两个模型使用相同的训练过程和相同的数据集。表1列出了用BLEU评分衡量的翻译性能。从表中可以明显看出,在所有情况下,这篇论文的RNNsearch都优于传统的RNNenc。更重要的是,当只考虑由已知单词组成的句子时,RNNsearch的性能与传统的基于短语的翻译系统(Moses)一样高。
Conclusion
In this paper, we proposed a novel architecture that addresses this issue. We extended the basic encoder–decoder by letting a model (soft-)search for a set of input words, or their annotations computed by an encoder, when generating each target word. We tested the proposed model, called RNNsearch, on the task of English-to-French translation. The experiment revealed that the proposed RNNsearch outperforms the conventional encoder–decoder model (RNNenc) significantly, regardless of the sentence length and that it is much more robust to the length of a source sentence.
这篇论文扩展了基本的编码器解码器结构,在生成每个目标单词时,让模型搜索一组输入单词或者由编码器计算它们的注释。这种结构在英法翻译任务中实现被称为RNNsearch的模型。实验结果表明,无论句子长度如何,该算法都比传统的编译码器模型(RNNenc)有明显的性能优势,并且对源语句的长度具有更强的鲁棒性
Effective Approaches to Attention-based Neural Machine Translation
Luong, M. T., Pham, H., & Manning, C. D. (2015). Effective approaches to attention-based neural machine translation. Conference Proceedings - EMNLP 2015: Conference on Empirical Methods in Natural Language Processing, 1412–1421. Retrieved from https://arxiv.org/pdf/1508.04025.pdf
Introduction
This paper examines two simple and effective classes of attentional mechanism: a global approach which always attends to all source words and a local one that only looks at a subset of source words at a time. Our ensemble model using different attention architectures yields a new state-of-the-art result in the WMT’15 English to German translation task with 25.9 BLEU points, an improvement of 1.0 BLEU points over the existing best system backed by NMT and an n-gram re-ranker.
这篇论文研究了两种简单而有效的注意机制:一种是全局方法,它始终关注所有源单词;另一种是局部方法,它一次只关注一个源单词子集。这篇论文的集成模型使用了不同的注意力架构,在WMT ‘ 15英德翻译任务中产生了一个新的最先进的结果,拥有25.9个BLEU点,比现有的由NMT和一个n-gram reranker支持的最佳系统提高了1.0个BLEU点。
Neural Machine Translation
A neural machine translation system is a neural network that directly models the conditional probability p(y|x) of translating a source sentence, x1, . . . , xn, to a target sentence, y1, . . . , ym. A basic form of NMT consists of two components: (a) an encoder which computes a representation s for each source sentence and (b) a decoder which generates one target word at a time.
神经机器翻译系统是直接模拟源句翻译的条件概率p(y|x)的神经网络。NMT的基本形式由两个组件组成:(A)一个编码器,它为每个源语句计算一个表示形式;(b)一个解码器,每次生成一个目标单词。
Attention-based Models
Our various attention-based models are classified into two broad categories, global and local. These classes differ in terms of whether the “attention” is placed on all source positions or on only a few source positions. We illustrate these two model types in Figure 2 and 3 respectively.
A global context vector ct is then computed as the weighted aver- age, according to at, over all the source states.
Unlike the global approach, the local alignment vector at is now fixed-dimensional, i.e., ∈ R2D+1. We consider two variants of the model as below.
Monotonic alignment (local-m) – we simply set pt = t assuming that source and target sequences are roughly monotonically aligned.
Predictive alignment (local-p) – instead of assuming monotonic alignments, our model predicts an aligned position as follows: pt = S · sigmoid(v⊤ p tanh(Wpht))
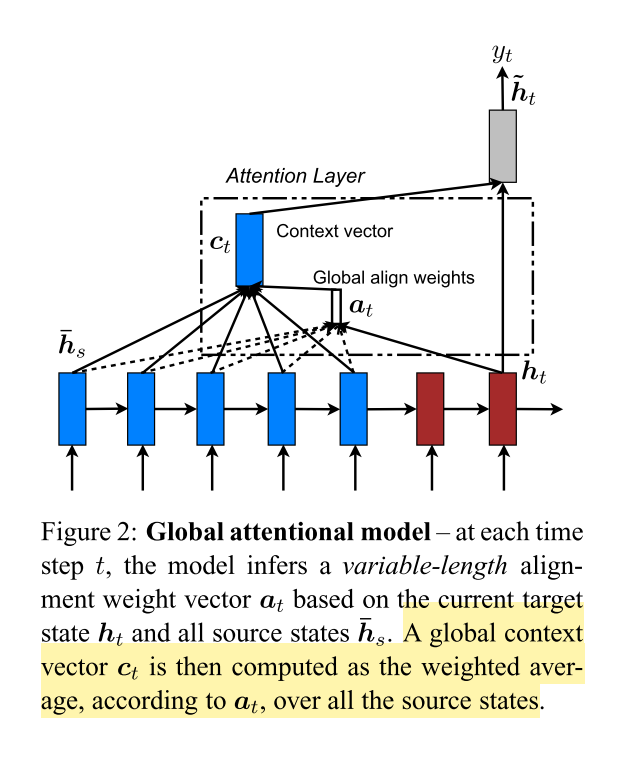
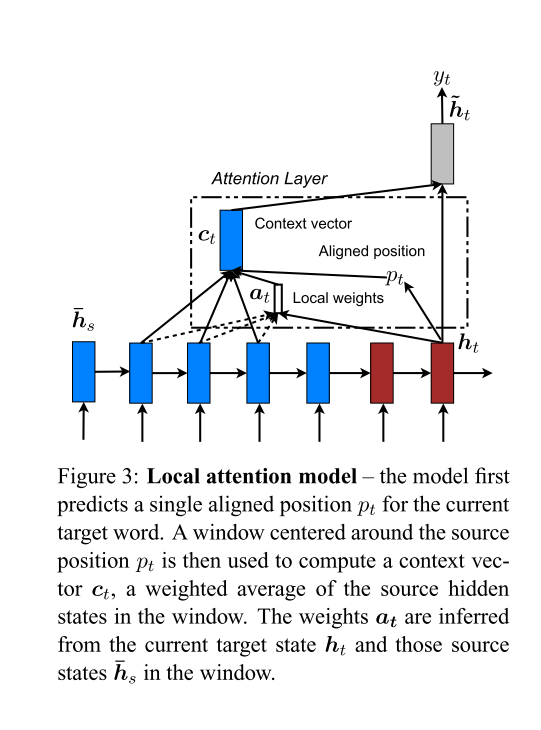
这篇论文的各种基于注意力的模型分为两大类,全局和局部。这两类的区别在于是将“注意力”放在所有源位置上,还是只放在少数源位置上。图2和图3分别演示了这两种模型类型。流程上来理解,全局和局部注意力机制唯一的不同就是生成语境向量的方法,接下来的步骤都是一样的。
全局注意力机制与soft_attention类似,但不同的是,全局注意力机制中的对齐向量的计算更简单,直接由当前隐状态和每一个输入隐状态计算得出权重,但全局注意力机制需要考虑所有的输入状态,所以计算开销较大。
为了解决全局注意力机制的计算开销较大问题,引入了局部注意力机制。局部注意力机制只会关注部分输入状态,论文中也给出了2种对齐的办法:1 就是直接认为pt=t,即认为source和target大致相当,剩下的权值计算方式和全局一致;2 就是根据以下公式计算:
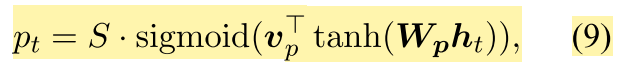
Experiments and Analysis
We evaluate the effectiveness of our models on the WMT translation tasks between English and German in both directions. new- stest2013 (3000 sentences) is used as a development set to select our hyperparameters. We report translation quality using two types of BLEU: (a) tokenized12 BLEU to be comparable with existing NMT work and (b) NIST13 BLEU to be comparable with WMT results.
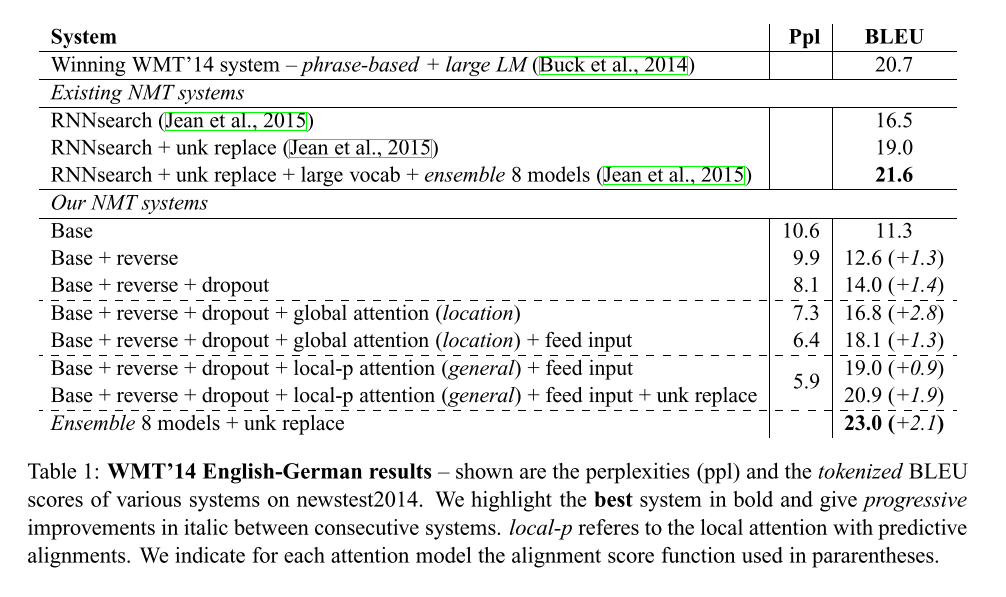
这篇论文评估了所提出模型在英语和德语双向翻译任务中的有效性。使用new- stest2013(3000句话)作为开发集来选择超参数,使用两种类型的BLEU报告翻译质量:(a)标记12 BLEU与现有的NMT工作相比较,(b) NIST13 BLEU与WMT结果相比较。
Conclusion
In this paper, we propose two simple and effective attentional mechanisms for neural machine translation: the global approach which always looks at all source positions and the local one that only attends to a subset of source positions at a time. We test the effectiveness of our models in the WMT translation tasks between English and German in both directions. For the English to German translation direction, our ensemble model has established new state-of-the-art results for both WMT’14 and WMT’15, outperforming existing best systems, backed by NMT models and n-gram LM re-rankers, by more than 1.0 BLEU.
这篇论文提出了两种简单而有效的神经机器翻译注意机制:全局方法总是关注所有的源位置;局部方法每次只关注源位置的子集。而所提出的集成模型,在WMT 15英德翻译任务中产生了一个新的最先进的结果。