BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. (Mlm). Retrieved from http://arxiv.org/abs/1810.04805
Introduction
There are two existing strategies for applying pre-trained language representations to downstream tasks: feature-based and fine-tuning. The feature-based approach, such as ELMo (Peters et al., 2018a), uses task-specific architectures that include the pre-trained representations as additional features. The fine-tuning approach, such as the Generative Pre-trained Transformer (OpenAI GPT) (Radford et al., 2018), introduces minimal task-specific parameters, and is trained on the downstream tasks by simply fine-tuning all pre- trained parameters. The two approaches share the same objective function during pre-training, where they use unidirectional language models to learn general language representations. We argue that current techniques restrict the power of the pre-trained representations, especially for the fine-tuning approaches. The major limitation is that standard language models are unidirectional, and this limits the choice of architectures that can be used during pre-training.
In this paper, we improve the fine-tuning based approaches by proposing BERT: Bidirectional Encoder Representations from Transformers. BERT alleviates the previously mentioned unidirectionality constraint by using a “masked language model” (MLM) pre-training objective. Unlike left-to- right language model pre-training, the MLM objective enables the representation to fuse the left and the right context, which allows us to pre- train a deep bidirectional Transformer.
这篇论文首先总结了现存的两种将预训练语言表示用于下游任务的方法,分别是基于特征的方法和微调方法。基于特征的方法比如ELMo,使用包含预训练表示的特定任务架构作为额外的特征。而微调方法比如OpenAI GPT,引入了最少的特定任务的参数,通过简单地微调所有预训练参数就可以完成在下游任务的训练。这两种方法在预训练过程中使用了同样的目标函数,它们都使用了单向的语言模型来学习通用的语言表示。但这篇论文认为使用单向语言模型会限制预训练表示的能力,尤其是在微调方法中,主要是限制了在预训练中能够被使用架构的选择。
在这篇论文中,作者改进了微调方法,提出了BERT,来自转换器的双向编码表示。BERT减少了单向模型对预训练模型的限制,主要是通过使用一个MLM预训练目标函数。不像从左到右的单向预训练模型,MLM目标函数能够让语言表示结合左右的文本,最终能够生成一个深度的双向转换器。
Related Work
ELMo and its predecessor generalize traditional word embedding research along a different dimension. They extract context-sensitive features from a left-to-right and a right-to-left language model. The contextual representation of each token is the concatenation of the left-to-right and right-to-left representations.
More recently, sentence or document encoders which produce contextual token representations have been pre-trained from unlabeled text and fine-tuned for a supervised downstream task (Dai and Le, 2015; Howard and Ruder, 2018; Radford et al., 2018). The advantage of these approaches is that few parameters need to be learned from scratch.
There has also been work showing effective transfer from supervised tasks with large datasets, such as natural language inference and machine translation.
这篇论文简单介绍了一些广泛使用的预训练语言表示方法。主要分为三类,分别是无监督的基于特征的方法,无监督的微调方法,以及从监督数据中迁移学习。
无监督的基于特征的方法中最具代表性的是ELMo方法,这种方法将传统的词向量研究从一个不同的维度进行了一般化。这种方法从从左到右和从右到左的语言模型中提取出了上下文敏感的特征。无监督的微调方法中表现良好的是OpenAI GPT,这种方法的一个优势就是需要学习的参数比较少。而关于迁移学习,主要就是从一些基于大数据集的监督学习任务(比如自然语言推断和机器翻译)中进行有效的迁移。
BERT
There are two steps in our framework: pre-training and fine-tuning. During pre-training, the model is trained on unlabeled data over different pre-training tasks. For fine- tuning, the BERT model is first initialized with the pre-trained parameters, and all of the parameters are fine-tuned using labeled data from the downstream tasks. Each downstream task has separate fine-tuned models, even though they are initialized with the same pre-trained parameters. The question-answering example in Figure 1 will serve as a running example for this section.
A distinctive feature of BERT is its unified architecture across different tasks. BERT’s model architecture is a multi-layer bidirectional Transformer encoder based on the original implementation described in Vaswani et al. (2017) and released in the tensor2tensor library. A “sequence” refers to the input token sequence to BERT, which may be a single sentence or two sentences packed together.
We pre-train BERT using two unsupervised tasks. One task is Masked LM, In order to train a deep bidirectional representation, we simply mask some percentage of the input tokens at random, and then predict those masked tokens. We refer to this procedure as a “masked LM” (MLM), although it is often referred to as a Cloze task in the literature . The other task is Next Sentence Prediction (NSP). In order to train a model that understands sentence relationships, we pre-train for a binarized next sentence prediction task that can be trivially generated from any monolingual corpus.
Fine-tuning is straightforward since the self- attention mechanism in the Transformer allows BERT to model many downstream tasks— whether they involve single text or text pairs—by swapping out the appropriate inputs and outputs.
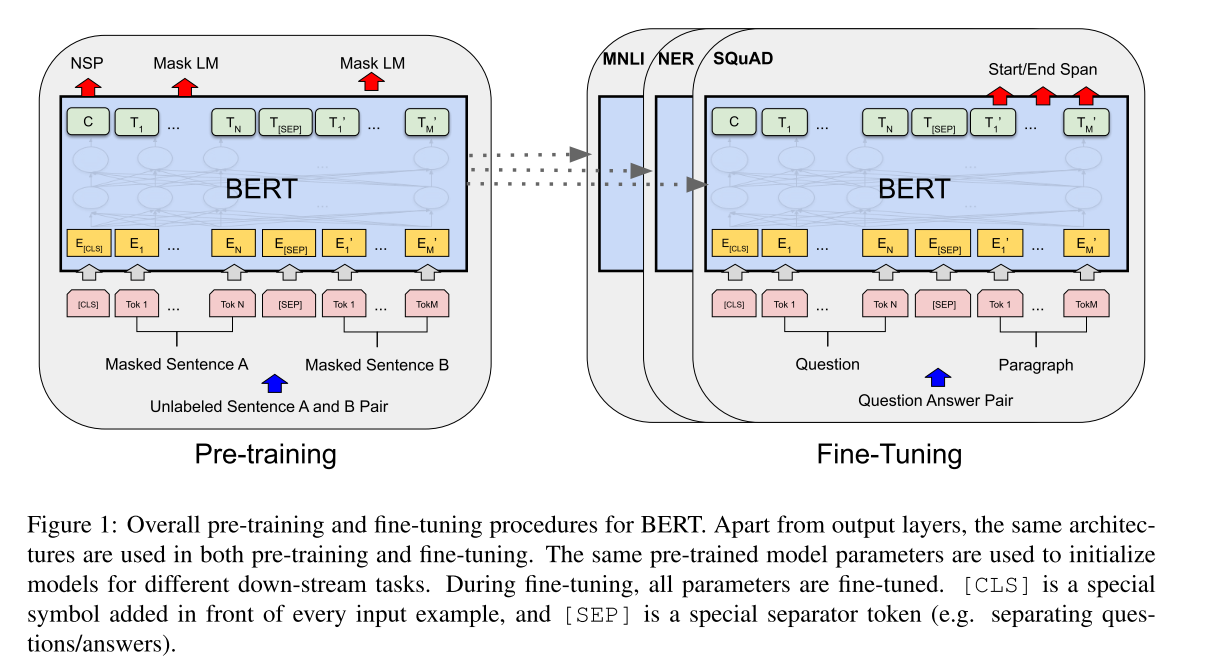
在BERT的框架中有两个步骤: 预训练和微调。在预训练中,使用不同训练任务的未标记数据进行训练。至于微调,首先使用预先训练的参数初始化BERT模型,然后使用来自下游任务的标记数据对所有参数进行微调。每个下游任务都有单独的微调模型,即使它们是用相同的预训练参数初始化的。图1中的问答示例大致表示了BERT的框架。
BERT的一个显著特征是它针对不同任务有统一架构。BERT的模型架构是一个多层双向转换器的编码器。BERT的输入序列可以是一个句子或两个组合在一起的句子。
我们使用两个非监督任务对BERT进行预训练。其中一个任务是Masked LM, 为了训练一个深层的双向表示,我们只需随机掩码输入符号的比例,然后预测这些掩码符号。我们将这个过程称为“Masked LM”(MLM)。另一项任务是下一句预测(NSP)。为了训练一个理解句子关系的模型,我们对一个可以由任何单语语料库生成的二值化下一句预测任务进行了预训练。
微调是相对简单的,因为转换器的自我注意机制允许BERT通过交换适当的输入和输出来为许多下游任务建模——无论是单个文本还是文本对。
Experiments
We present BERT fine-tuning results on some NLP tasks.
The General Language Understanding Evaluation (GLUE) benchmark (Wang et al., 2018a) is a collection of diverse natural language understanding tasks. Both BERTBASE and BERTLARGE outperform all systems on all tasks by a substantial margin, obtaining 4.5% and 7.0% respective average accuracy improvement over the prior state of the art.
The Stanford Question Answering Dataset (SQuAD v1.1) is a collection of 100k crowd- sourced question/answer pairs. Our best performing system outperforms the top leaderboard system by +1.5 F1 in ensemble and +1.3 F1 as a single system. In fact, our single BERT model outperforms the top ensemble system in terms of F1 score.
The SQuAD 2.0 task extends the SQuAD 1.1 problem definition by allowing for the possibility that no short answer exists in the provided para- graph, making the problem more realistic. We observe a +5.1 F1 improvement over the previous best system.
The Situations With Adversarial Generations (SWAG) dataset contains 113k sentence-pair completion examples that evaluate grounded common- sense inference. BERTLARGE out- performs the authors’ baseline ESIM+ELMo system by +27.1% and OpenAI GPT by 8.3%.
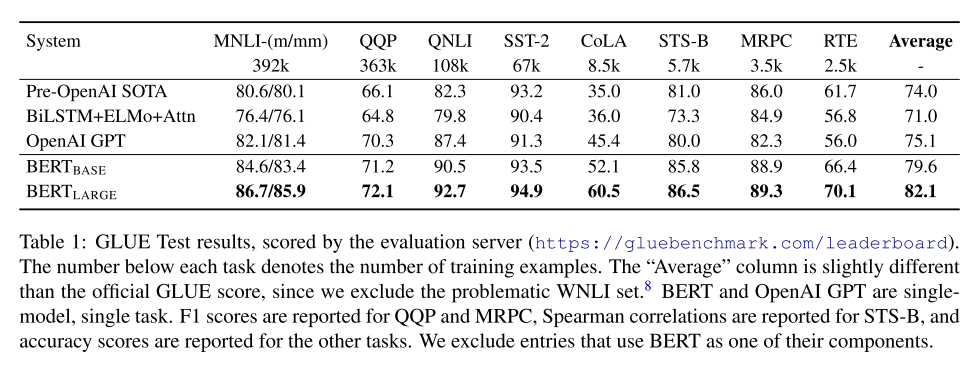
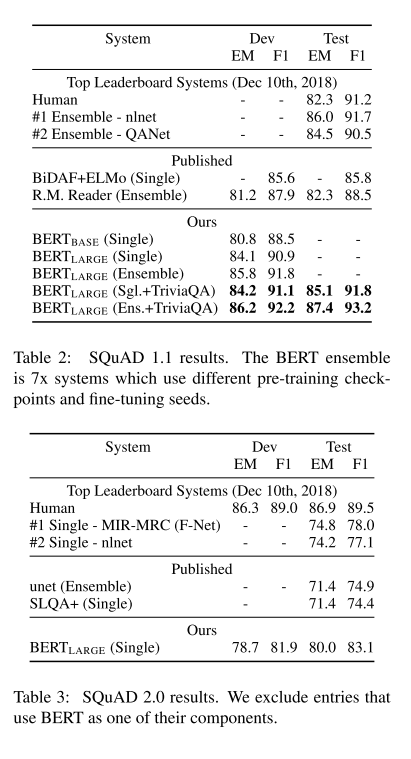
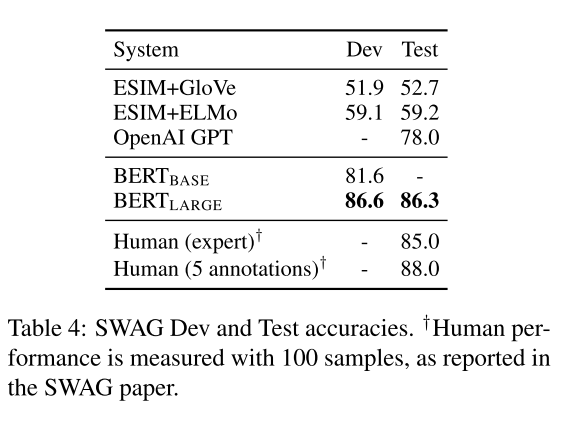
这篇论文在几个NLP任务上进行了实验,并给出了Bert微调方法的结果。在通用语言理解评估(GLUE),斯坦福问答数据集(sQuAD 1.1 ,2.0)和常识推理对抗数据集(SWAG)上面分别进行了实验,Bert在上面表现效果良好,甚至远远优于现有的最好方法。
Ablation Studies
We demonstrate the importance of the deep bidirectionality of BERT by evaluating two pre- training objectives using exactly the same pre- training data, fine-tuning scheme, and hyperparameters as BERTBASE. We trained a number of BERT models with a differing number of layers, hidden units, and attention heads, while otherwise using the same hyperparameters and training procedure as described previously. We compare the two approaches by applying BERT to the CoNLL-2003 Named Entity Recognition (NER) task. BERT is effective for both fine- tuning and feature-based approaches.
这篇论文为了说明Bert的重要性,进行了一系列对比试验(即Ablation Study)。这些实验分别说明了预训练任务的影响,模型大小的影响,以及通过基于特征的Bert方法的实验说明了BERT对于微调和基于特征的方法都很有效。
Conclusion
Our major contribution is further generalizing some existing findings to deep bidirectional architectures, allowing the same pre-trained model to successfully tackle a broad set of NLP tasks.
这篇论文的主要贡献是进一步将一些现有的发现推广到深层双向架构,能够使用相同的预训练模型成功地处理广泛的NLP任务。
Deep contextualized word representations
Peters, M., Neumann, M., Iyyer, M., Gardner, M., Clark, C., Lee, K., & Zettlemoyer, L. (2018). Deep Contextualized Word Representations. 2227–2237. https://doi.org/10.18653/v1/n18-1202
Introduction
We use vectors derived from a bidirectional LSTM that is trained with a coupled language model (LM) objective on a large text corpus. For this reason, we call them ELMo (Embeddings from Language Models) representations. ELMo representations are deep, in the sense that they are a function of all of the internal layers of the biLM. More specifically, we learn a linear combination of the vectors stacked above each input word for each end task, which markedly improves performance over just using the top LSTM layer.
Extensive experiments demonstrate that ELMo representations work extremely well in practice.
这篇论文使用了一个双向LSTM向量,这个向量在大型文本语料库中由一个耦合的语言模型(LM)目标训练而来,因此,本文称它是ELMo表示(语言模型的嵌入),ELMo表示是深层次的,因为它是biLM所有内层的函数。具体来说,ELMo学习了一个向量的线性组合,这些向量堆叠在每个输入词之上,为每个结束任务使用,这样相比于仅仅使用顶层的LSTM层,显著地改善了性能。这篇论文给出了一些实验来证明ELMo表示在实践中表现效果良好。
Related Work
In this paper, we take full advantage of access to plentiful monolingual data, and train our biLM on a corpus with approximately 30 million sentences. We also generalize these approaches to deep contextual representations, which we show work well across a broad range of diverse NLP tasks.
In contrast, after pretraining the biLM with unlabeled data, we fix the weights and add additional task- specific model capacity, allowing us to leverage large, rich and universal biLM representations for cases where downstream training data size dictates a smaller supervised model.
这篇论文充分利用了对大量单语数据的访问,并在一个约有3000万个句子的语料库上训练biLM。这篇论文还将这些方法推广到深层上下文表示,这些方法可以很好地处理各种NLP任务。此外,在使用未标记的数据对biLM进行预训练之后,这篇论文确定了权重,并添加了额外的特定于任务的模型容量,从而能够利用大型、丰富和通用的biLM表示来处理下游训练数据大小要求较小的监督模型的情况。
ELMo: Embeddings from Language Models
Unlike most widely used word embedding, ELMo word representations are functions of the entire input sentence. They are computed on top of two-layer biLMs with character convolutions , as a linear function of the internal network states. This setup allows us to do semi-supervised learning, where the biLM is pre- trained at a large scale and easily incorporated into a wide range of existing neural NLP architectures.
A biLM combines both a forward and backward LM. Our formulation jointly maximizes the log likelihood of the forward and backward directions. We share some weights between directions instead of using completely independent parameters.
ELMo is a task specific combination of the intermediate layer representations in the biLM. To add ELMo to the supervised model, we first freeze the weights of the biLM and then concatenate the ELMo vector ELMo(task k) with x(k)and pass the ELMo enhanced representation [x(k); ELMo(task k) ] into the task RNN. Finally, we found it beneficial to add a moderate amount of dropout to ELMo.
Once pretrained, the biLM can compute representations for any task. In some cases, fine tuning the biLM on domain specific data leads to significant drops in perplexity and an increase in downstream task performance.
与最广泛使用的单词嵌入不同,ELMo单词表示是整个输入语句的函数。它们是在带有字符卷积的两层biLMs上计算的,并作为内部网络状态的线性函数。这种设置允许进行半监督学习,其中biLM是预先在大规模数据中训练的,并很容易纳入现有的神经NLP架构的广泛范围。
biLM结合了正向LM和反向LM。这篇论文的公式最大化了正向和反向的对数可能性,在方向之间共享一些权重,而不是使用完全独立的参数。
ELMo是biLM中中间层表示形式的特定于任务的组合。为了将ELMo添加到监督模型中,首先冻结biLM的权值,然后将ELMo向量ELMo(task k)与x(k)连接起来,将ELMo的增强表示[x(k);ELMo(task k)传递到任务RNN中。最后发现在ELMo中添加适量的dropout是能够提升性能的。
经过预训练后,biLM可以为任何任务计算表示形式。在某些情况下,对领域特定数据的biLM进行微调会显著降低复杂性,并提高下游任务性能。
Evaluation
Table 1 shows the performance of ELMo across a diverse set of six benchmark NLP tasks. In every task considered, simply adding ELMo establishes a new state-of-the-art result, with relative error reductions ranging from 6 - 20% over strong base models. This is a very general result across a diverse set model architectures and language understanding tasks.
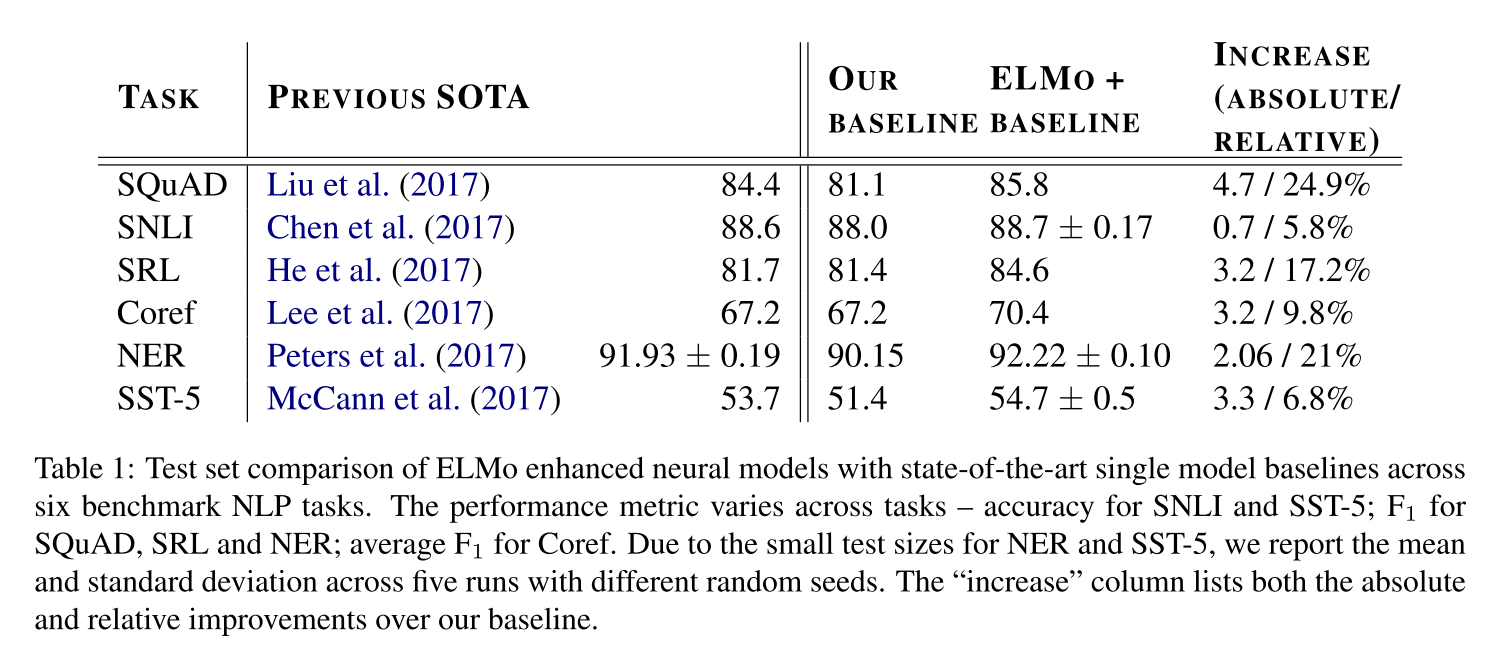
表1显示了ELMo在6个基准NLP任务中的性能。在考虑的每一个任务中,简单地添加ELMo就可以建立一个新的最先进的结果,相对于强基础模型,误差降低了6 - 20%。这是一个非常普遍的结果,适用于不同的集合模型体系结构和语言理解任务。
Analysis
This section provides an ablation analysis to validate our chief claims and to elucidate some interesting aspects of ELMo representations. Using deep contextual representations in downstream tasks improves performance over previous work that uses just the top layer. Additionally, we analyze the sensitivity to where ELMo is included in the task model, training set size, and visualize the ELMo learned weights across the tasks.
这篇论文在这部分进行了控制变量分析,以验证论文的主要观点,并介绍了一些ELMo表示有趣的方面。首先,验证了在下游任务中使用深层上下文表示比只使用顶层的先前工作提高了性能。此外,这部分还分析了ELMo在任务模型中的位置、训练集大小的敏感性,并可视化了ELMo在任务中学习到的权重。
Conclusion
We have introduced a general approach for learning high-quality deep context-dependent representations from biLMs, and shown large improvements when applying ELMo to a broad range of NLP tasks. the biLM layers efficiently encode different types of syntactic and semantic information about words- in-context, and using all layers improves overall task performance.
我们介绍了一种从biLMs学习的高质量深度上下文相关表示的通用方法ELMo,并将ELMo应用于广泛的NLP任务,相比之前的方法有很大改进。此外,biLM层可以有效地编码关于上下文中的单词的不同类型的语法和语义信息,并且使用所有层可以提高整体任务性能。
Fine-tuning Pre-Trained Transformer Language Models to Distantly Supervised Relation Extraction
Alt, C., Hübner, M., & Hennig, L. (2019). Fine-tuning Pre-Trained Transformer Language Models to Distantly Supervised Relation Extraction. Retrieved from http://arxiv.org/abs/1906.08646
Introduction
Relation extraction (RE), defined as the task of identifying the relationship between concepts mentioned in text, is a key component of many natural language processing applications. Current state-of-the-art RE methods try to address these challenges by applying multi-instance learning methods and guiding the model by explicitly provided semantic and syntactic knowledge. However, we observe that these models are often biased towards recognizing a limited set of relations with high precision, while ignoring those in the long tail.
In this paper, we introduce a Distantly Supervised Transformer for Relation Extraction (DISTRE). We extend the standard Transformer architecture by a selective attention mechanism to handle multi-instance learning and prediction, which allows us to fine-tune the pre-trained Transformer language model directly on the distantly supervised RE task. This minimizes explicit feature extraction and reduces the risk of error accumulation. We selected the GPT as our language model because of its fine-tuning efficiency and reasonable hardware requirements, compared to e.g. LSTM- based language models or BERT.
关系提取(RE)是许多自然语言处理应用程序的关键组成部分,它是指识别文本中提到的概念之间的关系。目前最先进的RE方法试图通过应用多实例学习方法来解决关系提取中遇到的问题,并通过显式提供语义和语法知识来指导模型。然而,这些方法往往倾向于识别一组有限的高精度关系,而忽略了长远的关系。
这篇论文介绍了一种用于关系提取的远距离监督Transformer。通过选择性注意机制扩展了标准的Transformer体系结构,以处理多实例学习和预测,这样能够在远距离监督任务上直接微调预训练的Transformer语言模型。这使得显式特征提取最小化,并降低了错误积累的风险。这篇论文选择GPT作为语言模型,是因为和基于LSTM的语言模型或BERT相比,它的微调效率较高以及硬件需求合理。
Transformer Language Model
The Transformer-Decoder (Liu et al., 2018a), shown in Figure 2, is a decoder-only variant of the original Transformer (Vaswani et al., 2017). Like the original Transformer, the model repeatedly encodes the given input representations over multiple layers (i.e., Transformer blocks), consisting of masked multi-head self-attention followed by a position-wise feedforward operation. In contrast to the original decoder blocks this version contains no form of unmasked self-attention since there are no encoder blocks.
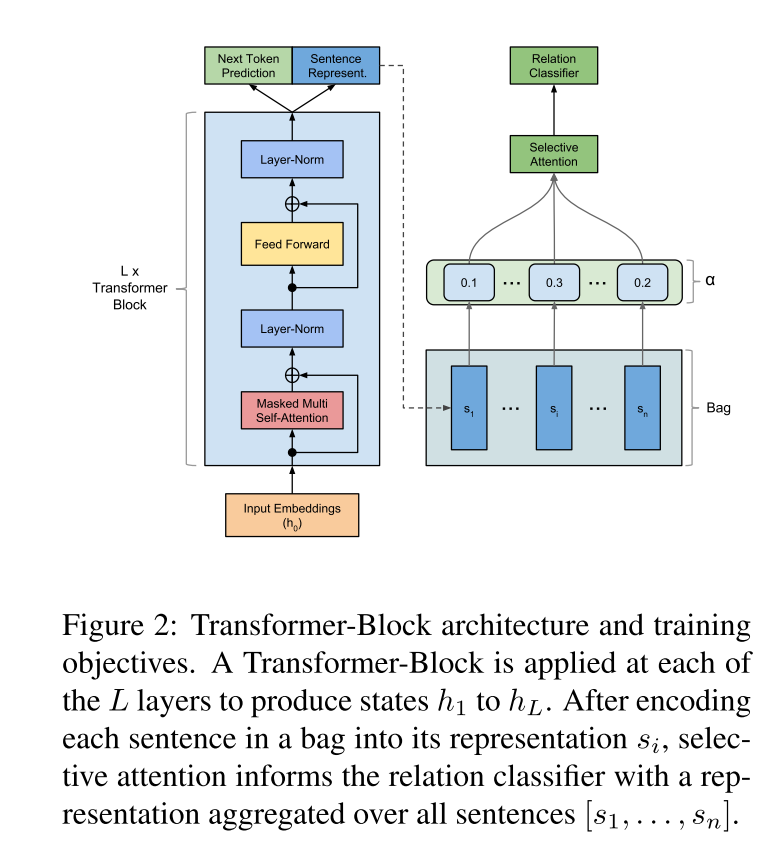
Transformer译码器(Liu et al., 2018a),如图2所示,是原Transformer(Vaswani et al., 2017)的纯译码器变体。与原始的转换器一样,该模型在多个层重复编码给出的输入表示,包括掩蔽的多头自注意机制,然后是一个位置明确的前馈操作。与原始解码器块相比,它不包含任何形式的非屏蔽自我注意,因为没有编码器块。
Multi-Instance Learning with the Transformer
Our input representation (see Figure 3) encodes each sentence as a sequence of tokens. To make use of sub-word information, we tokenize the in- put text using byte pair encoding (BPE) (Sennrich et al., 2016). The BPE algorithm creates a vocabulary of sub-word tokens, starting with single characters. Then, the algorithm iteratively merges the most frequently co-occurring tokens into a new token until a predefined vocabulary size is reached. For each token, we obtain its input representation by summing over the corresponding token embed- ding and positional embedding
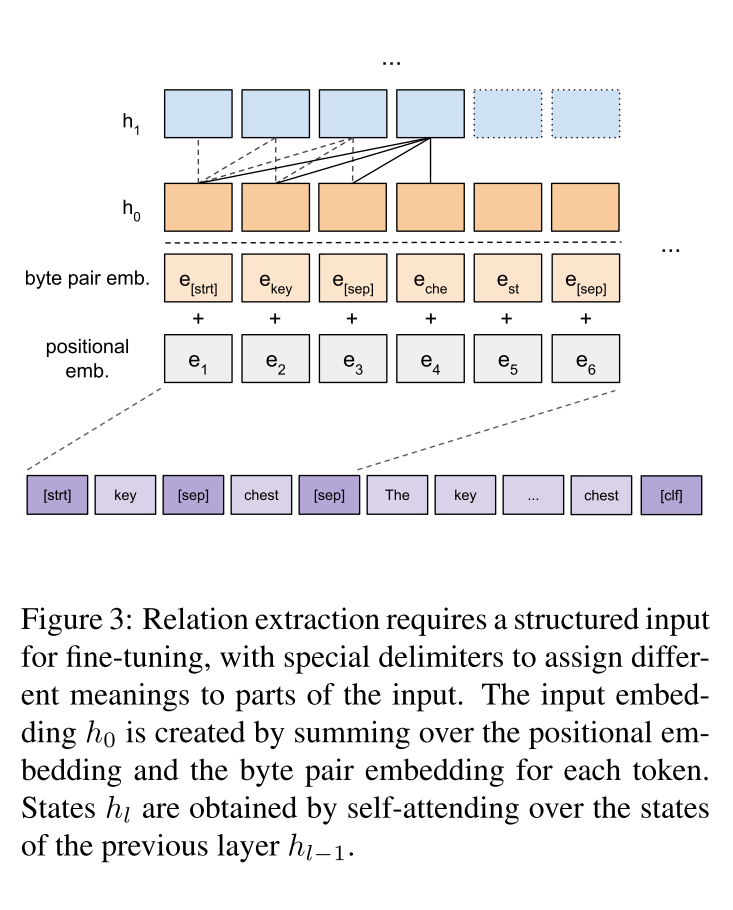
这篇论文的输入表示(参见图3)将每个句子编码为标记序列。为了利用子单词信息,使用字节对编码(BPE)对输入文本进行标记(Sennrich et al., 2016)。BPE算法创建子单词标记的词汇表,以单个字符开始,然后,该算法迭代地将最频繁同时出现的标记合并到一个新的token中,直到达到预定义的词汇表大小。对于每个token,通过对相应的token嵌入和位置嵌入求和,得到其输入表示形式。
Experiment Setup
We run our experiments on the distantly supervised NYT10 dataset and use PCNN+ATTN (Lin et al., 2016) and RESIDE (Vashishth et al., 2018) as the state-of-the- art baselines.
The piecewise convolutional neural network (PCNN) segments each input sentence into parts to the left, middle, and right of the entity pair, followed by convolutional encoding and selective attention to inform the relation classifier with a bag- level representation. RESIDE, on the other hand, uses a bidirectional gated recurrent unit (GRU) to encode the input sentence, followed by a graph convolutional neural network (GCN) to encode the explicitly provided dependency parse tree information. This is then combined with named entity type information to obtain a sentence representation that can be aggregated via selective attention and forwarded to the relation classifier.
The NYT10 dataset by Riedel et al. (2010) is a standard benchmark for distantly supervised relation extraction. Since pre-training is computationally expensive, and our main goal is to show its effectiveness by fine-tuning on the distantly supervised relation extraction task, we reuse the language model published by Radford et al. (2018) for our experiments. During our experiments we found the hyperparameters for fine-tuning, reported in Radford et al. (2018), to be very effective.
这篇论文在远程监督NYT10数据集上运行实验,使用PCNN+ATTN (Lin et al., 2016)和RESIDE (Vashishth et al., 2018)作为最先进的基准方法。
分段卷积神经网络(PCNN)将每个输入语句分割成实体对的左、中、右三个部分,然后进行卷积编码和选择性注意,以袋式表示的形式通知关系分类器。另一方面,RESIDE使用双向门控循环单元(GRU)对输入语句进行编码,然后使用图卷积神经网络(GCN)对显式提供的依赖解析树信息进行编码。之后将其与命名实体类型信息相结合,获得一个句子表示形式,这个表示形式可以通过选择性注意进行聚合并转发给关系分类器。
NYT10数据集是用于远程监督关系提取的标准数据集。由于预训练的计算开销很大,而主要目标是通过对远程监督关系提取任务进行微调来显示其有效性,因此这篇论文在实验中重用了Radford等人(2018)发表的语言模型。在实验中,这篇论文发现Radford等人(2018)报道的微调超参数非常有效。
Results
Table 1 shows the results of our model on the held-out dataset. DISTRE with selective attention achieves a new state-of-the-art AUC value of 0.422. The precision-recall curve in Figure 4 shows that it outperforms RESIDE and PCNN+ATT at higher recall levels, while precision is lower for top predicted relation instances.
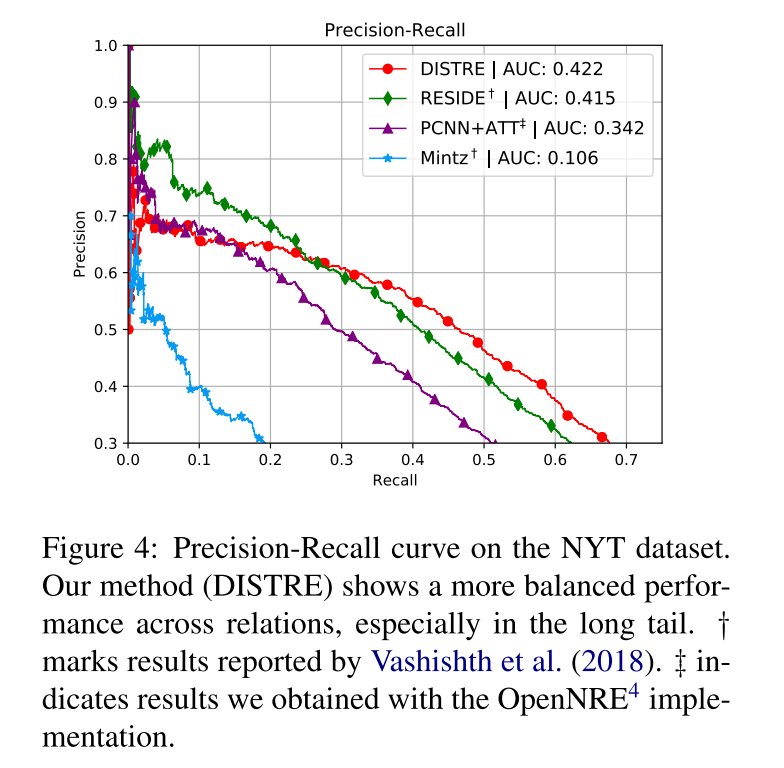
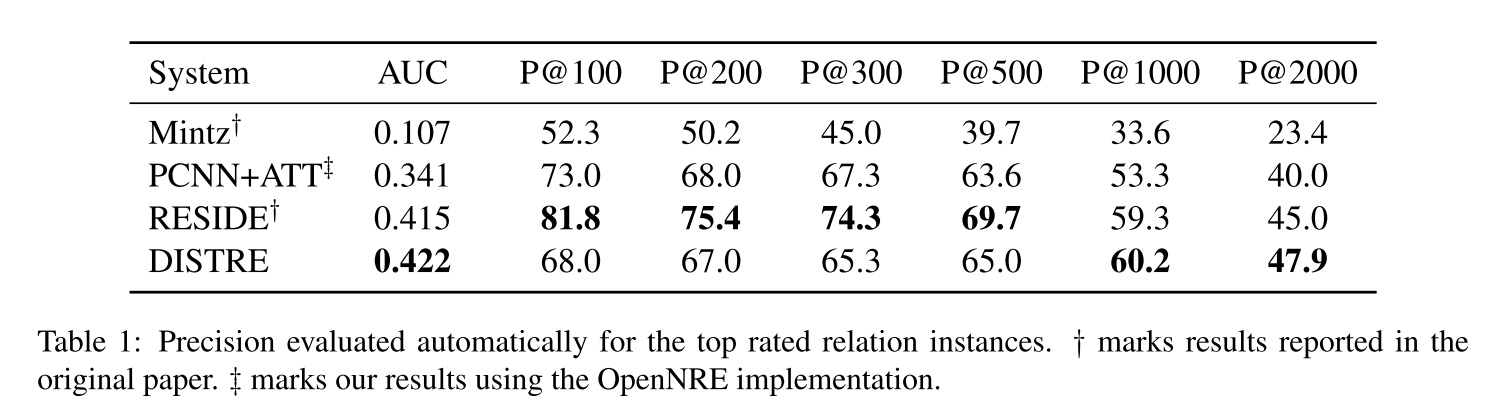
表1显示了模型在helout数据集上的结果,具有选择性注意的DISTRE达到了最新的AUC值0.422。图4中的precision-recall曲线显示,在较高的recall级别上,它的性能优于RESIDE 和PCNN+ATT,而对于顶级预测关系实例,它的精度较低。
Conclusion
We proposed DISTRE, a Transformer which we extended with an attentive selection mechanism for the multi-instance learning scenario, common in distantly supervised relation extraction. While DISTRE achieves a lower precision for the 300 top ranked predictions, we observe a state-of-the-art AUC (Area Under Curve) and an overall more balanced performance.
这篇论文提出了一种用于多实例学习场景的Transformer ,它是一种常用的远程监督关系提取方法。虽然对于300个排名靠前的预测,新版本的精度较低,但它有最先进的AUC和整体更平衡的性能。