Neural Architecture Search with Reinforcement Learning
Zoph, B., & Le, Q. V. (2016). Neural Architecture Search with Reinforcement Learning. 1–16. Retrieved from http://arxiv.org/abs/1611.01578
Introduction
Although Neural Architecture Application has become easier, designing architectures still requires a lot of expert knowledge and takes ample time. This paper presents Neural Architecture Search, a gradient-based method for finding good architectures (see Figure 1) . It is based on the observation that the structure and connectivity of a neural network can be typically specified by a variable-length string. It is therefore possible to use a recurrent network – the controller – to generate such string. Training the network specified by the string – the “child network” – on the real data will result in an accuracy on a validation set. Using this accuracy as the reward signal, we can compute the policy gradient to update the controller. As a result, in the next iteration, the controller will give higher probabilities to architectures that receive high accuracies. In other words, the controller will learn to improve its search over time.
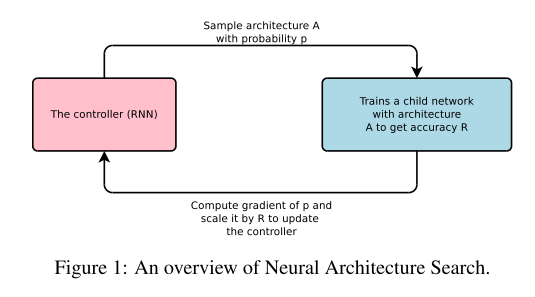
神经网络架构的应用虽然比较广泛,但是设计神经网络架构依旧需要花费很多资源和时间。鉴于此,这篇论文提出了一个基于梯度算法的方法来搜索出最优的神经网络架构,这种方法也基于一个事实——神经网络的结构和连接通常能够被一个变长的字符串指定。因此,这篇论文提出了一个循环网络,这个循环网络包含一个控制器和一个“子网络”,控制器用于产生这样的变长字符串,之后根据这个字符串训练出相应的“子网络”, 并在验证集上进行验证,产生一个准确度,然后把这个准确度作为一个反馈信号,计算出策略梯度来更新控制器,因此,在下一次迭代中,控制器将会有更高概率产生高准确率的架构,换句话说,控制器将慢慢地优化对神经网络的搜索。
Related Work
Hyperparameter optimization is an important research topic in machine learning, and is widely used in practice. Despite their success, these methods are still limited in that they only search models from a fixed-length space. There are Bayesian optimization methods that allow to search non fixed length architectures (Bergstra et al., 2013; Mendoza et al., 2016), but they are less general and less flexible than the method proposed in this paper.
Modern neuro-evolution algorithms,are much more flexible for composing novel models, yet they are usually less practical at a large scale.The controller in Neural Architecture Search is auto-regressive, which means it predicts hyperparameters one a time, conditioned on previous predictions. This idea is borrowed from the decoder in end-to-end sequence to sequence learning (Sutskever et al., 2014). Unlike sequence to sequence learning, our method optimizes a non-differentiable metric, which is the accuracy of the child network. It is therefore similar to the work on BLEU optimization in Neural Machine Translation (Ran- zato et al., 2015; Shen et al., 2016). Unlike these approaches, our method learns directly from the reward signal without any supervised bootstrapping.
超参数调优是在机器学习里是一个重要的研究课题,有好多方法都能得到好的效果,但是他们均只能在固定长度神经网络的搜索空间里搜索模型,另外,贝叶斯优化的方法虽然能够让这些方法搜索不定长的架构,但是这样的方法没有这篇论文中的方法更灵活。
一些现代的神经网络进化算法,在生成模型时更为灵活,但是它们通常不能用于大规模的计算。
在本文神经网络搜索里的控制器是自动回归的,也就是说它能基于之前的预测更新超参数。这个思想类似于端到端的序列学习里的解码器,但本文与之不同的是,本文的方法优化了一个不可微分的度量,这个度量是子网络的准确度。而这个度量的思想又类似于BLEU在神经网络机器翻译上的优化,但与这些方法不同的是,本文的方法直接按照反馈信息优化,而不需要监督指令。
Methods
Generate Model Descriptions with A Controller Recurrent Neural Network(通过控制器循环网络产生模型)
The process of generating an architecture stops if the number of layers exceeds a certain value. This value follows a schedule where we increase it as training progresses. Once the controller RNN finishes generating an architecture, a neural network with this architecture is built and trained. At convergence, the accuracy of the network on a held-out validation set is recorded. The parameters of the controller RNN, θc, are then optimized in order to maximize the expected validation accuracy of the proposed architectures.
如果网络层的数量超过了一个确定的值,那么产生神经网络架构的过程将会停止,其中这个确定的值是随着训练进程不断增加的。一旦循环网络控制器停止产生神经网络架构,那么,基于这个架构的神经网络则会被构建和训练,当神经网络趋于收敛时,这个神经网络在被留出的验证集上的准确度将会被记录。接着循环网络控制器的参数θc 将会被优化,以便产生最大期望验证集准确率的神经架构。
Training with Reinforce(利用强化学习进行训练)
Use this accuracy R as the reward signal and use reinforcement learning to train the controller. More concretely, to find the optimal architecture, we ask our controller to maximize its expected reward. Since the reward signal R is non-differentiable, we need to use a policy gradient method to iteratively update θc.
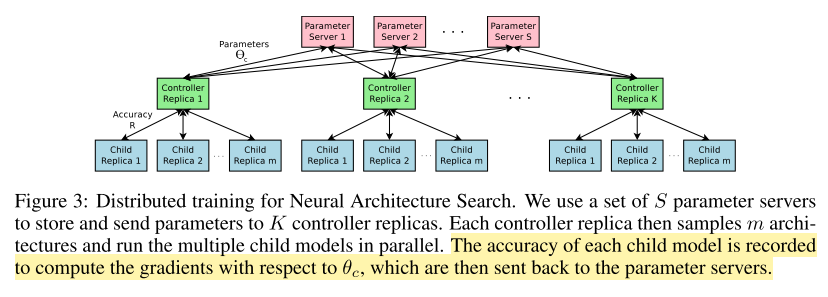
As training a child network can take hours, we use distributed training and asynchronous parameter updates in order to speed up the learning process of the controller . We use a parameter-server scheme where we have a parameter server of S shards, that store the shared parameters for K controller replicas. Each controller replica samples m different child architectures that are trained in parallel. The controller then collects gradients according to the results of that minibatch of m architectures at convergence and sends them to the parameter server in order to update the weights across all controller replicas. In our implementation, convergence of each child network is reached when its training exceeds a certain number of epochs. This scheme of parallelism is summarized in Figure 3
这篇论文使用模型准确度R作为反馈信号,并使用强化学习来训练控制器,具体来讲,为了找到最优的架构,控制器需要产生一个有最大准确度的模型架构。但是因为反馈信号R是不可微分的,所以这篇文章使用策略梯度方法来迭代更新控制器参数θc。
因为训练一个子网络会耗费大量时间,这篇论文采用了分布式训练和异步参数更新的方法来加快控制器的训练进程。这个方法具体来讲就是,使用一组s个参数服务器分片,这组参数服务器包含着k个控制器副本的参数,并且s个参数服务器向这k个控制器副本提供参数。而每个控制器副本分成m个不同的子架构,并且这每个不同的子架构平行训练,训练后的准确度将会被记录,然后计算关于控制器参数θc的梯度,而这个梯度将会被返回到参数服务器,进行迭代更新。
Increase Architecture Complexity with Skip Connections and Other Layer Types(通过跳过连接来增加结构复杂度以及其他网络层类型)
We introduce a method that allows our controller to propose skip connections or branching layers, thereby widening the search space. To enable the controller to predict such connections, we use a set-selection type attention which was built upon the attention mechanism. At layer N, we add an anchor point which has N− 1 content-based sigmoids to indicate the previous layers that need to be connected. Each sigmoid is a function of the current hidden state of the controller and the previous hidden states of the previous N − 1 anchor points. We then sample from these sigmoids to decide what previous layers to be used as inputs to the current layer.
To be able to add more types of layers, we need to add an additional step in the controller RNN to predict the layer type, then other hyperparameters associated with it.
这篇论文介绍了一种方法,这种方法能够让控制器跳过连接或分支层,进而可以拓宽搜索空间。这种方法引入了注意力机制,在控制器网络第N层增加了一个定位点,这个定位点有N-1个表示前面需要连接的网络层的激活函数。每一个激活函数都是一个关于当前层隐藏状态和前n-1个定位点隐藏状态的函数。这种方法就会根据这个函数来确定前面的网络层是否作为当前层的输入。
为了能够增加更多类型的网络层(不仅仅是卷积层,还有池化层,标准化层等),需要在控制器的循环神经网络中增加一个额外的步骤来预测网络层的类型和与之关联一些的超参数。
Generate Recurrent Cell Architectures(产生循环网络架构)
The computations for basic RNN and LSTM cells can be generalized as a tree of steps that take xt and ht−1 as inputs and produce ht as final output. The controller RNN needs to label each node in the tree with a combination method (addition, elementwise multiplication, etc.) and an activation function (tanh, sigmoid, etc.) to merge two inputs and produce one output. Two outputs are then fed as inputs to the next node in the tree. To allow the controller RNN to select these methods and functions, we index the nodes in the tree in an order so that the controller RNN can visit each node one by one and label the needed hyperparameters.
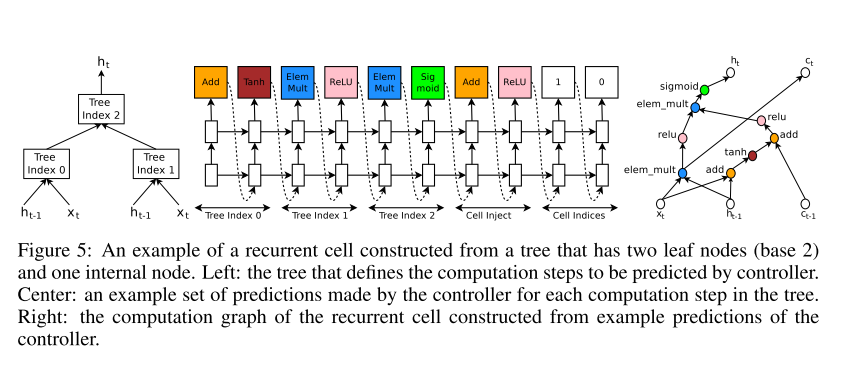
基本的RNN和LSTM结构的计算,能够被一般化为一棵阶梯树,它以xt和h(t-1)作为输入,产生h(t)作为最后输出。这个控制器循环网络需要标注在阶梯树里的每个节点,并且使用一个结合方法和一个激活函数来合并两个输入并产生一个输出,两个输出之后又被作为树中下一个节点的输入。为了允许控制器循环网络能够选择这些方法和函数,这里为阶梯树上的每一个节点按照次序创建了索引,以便控制器循环网络能够依次遍历每一个节点,并且标注需要的超参数。
Experiments and Results
Learning Convolutional Architectures For CIFAR-10(在CIFAR-10数据集上学习卷积神经网络)
Training details: The controller RNN is a two-layer LSTM with 35 hidden units on each layer. It is trained with the ADAM optimizer (Kingma & Ba, 2015) with a learning rate of 0.0006. The weights of the controller are initialized uniformly between -0.08 and 0.08. For the distributed train- ing, we set the number of parameter server shards S to 20, the number of controller replicas K to 100 and the number of child replicas m to 8, which means there are 800 networks being trained on 800 GPUs concurrently at any time.
Once the controller RNN samples an architecture, a child model is constructed and trained for 50 epochs. The reward used for updating the controller is the maximum validation accuracy of the last 5 epochs cubed. The validation set has 5,000 examples randomly sampled from the training set, the remaining 45,000 examples are used for training. The settings for training the CIFAR-10 child models are the same with those used in Huang et al. (2016a). We use the Momentum Optimizer with a learning rate of 0.1, weight decay of 1e-4, momentum of 0.9 and used Nesterov Momentum (Sutskever et al., 2013).
During the training of the controller, we use a schedule of increasing number of layers in the child networks as training progresses. On CIFAR-10, we ask the controller to increase the depth by 2 for the child models every 1,600 samples, starting at 6 layers.Results:
训练细节:控制器循环网络采用两层的LSTM,每层有35个隐藏单元,并采用学习率是0.0006的ADAM优化器。控制器的初始换权重是在-0.08到0.08之间。对于分布式训练来讲,参数服务器分片S是20个,控制器副本K是100个,子网络架构m是8个,所以总共可以有800个网络同时在800个GPU上训练。每一个子网络架构训练50各阶段,更新控制器使用的反馈参数是最后五个阶段中最大的验证准确率。验证集是从训练数据中随机选择的5000个样本,而剩下的45000个样本则作为训练集。在训练控制器的过程中,使用了一个随时间增长的子网络层数,初始层数是6层,每训练1600个样本就增加2层。
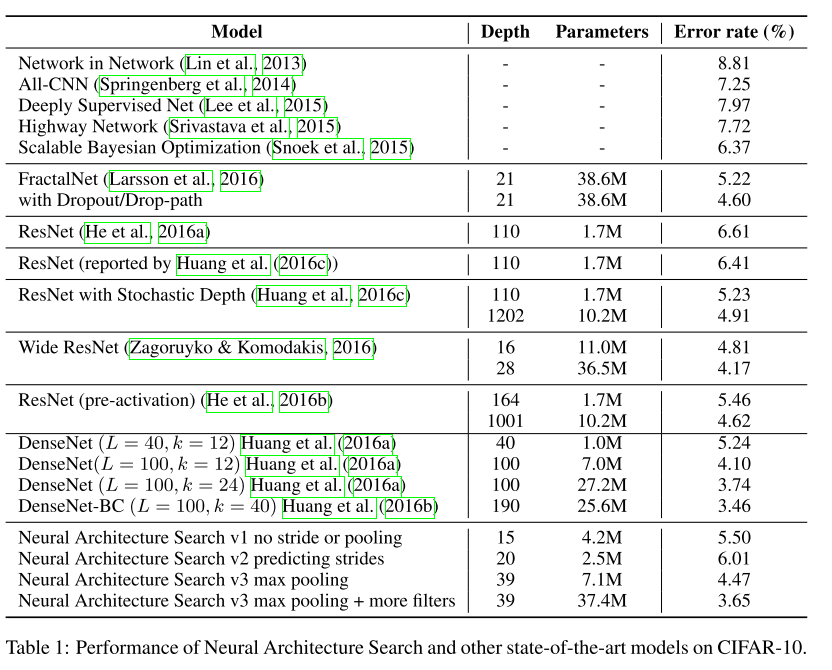
训练结果:神经网络架构搜索能够设计几个表现优良的网络架构,其在CIFAR-10上的表现性能和一些最好的模型差不多。
Learning Recurrent Cells for Penn TreeBank(在PTB数据集上学习循环神经网络)
Training details: The controller and its training are almost identical to the CIFAR-10 experiments except for a few modifications: 1) the learning rate for the controller RNN is 0.0005, slightly smaller than that of the controller RNN in CIFAR-10, 2) in the distributed training, we set S to 20, K to 400 and m to 1, which means there are 400 networks being trained on 400 CPUs concurrently at any time, 3) during asynchronous training we only do parameter updates to the parameter-server once 10 gradients from replicas have been accumulated.
Results:
训练细节:这个实验的控制器循环网络和训练与上面(CIFAR-10)的实验类似,主要有以下几个不同:
- 优化器的学习率是0.005;
- 分布式训练中,参数服务器S是20个,控制器副本K是400个,子网络架构m是1个;
- 在异步训练中,只有控制器副本积累到10个梯度时才更新参数服务器的参数。
训练结果:神经网络搜索获取到的模型在该数据集上表现优于其他一些先进的模型。另外,还可以将获取到的模型通过迁移学习使用在其他的问题解决上。
Conclusion
Neural Architecture Search is an idea of using a recurrent neural network to compose neural network architectures. By using recurrent network as the controller, our method is flexible so that it can search variable-length architecture space. Our method has strong empirical performance on very challenging benchmarks and presents a new research direction for automatically finding good neural network architectures.
NAS是一种使用循环神经网络生成神经网络架构的想法,通过使用循环神经网络作为控制器,这种方法能够很灵活的用于搜索变长的架构空间,而且在一些数据集上具有很好的实验性能,为自动化查找神经网络架构提供了一个新的研究方向。
Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation
Liu, C., Chen, L.-C., Schroff, F., Adam, H., Hua, W., Yuille, A., & Fei-Fei, L. (2019). Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation. Retrieved from http://arxiv.org/abs/1901.02985
Introduction
In this paper, we study Neural Archi- tecture Search for semantic image segmentation, an important computer vision task that assigns a label like “person” or “bicycle” to each pixel in the input image.
The vast majority of current works on NAS follow this two-level hierarchical design, but only automat- ically search the inner cell level while hand-designing the outer network level. We propose a network level architecture search space that augments and complements the much-studied cell level one, and consider the more challenging joint search of network level and cell level architectures.
We develop a differentiable, continuous formulation that conducts the two-level hierarchical architecture search efficiently in 3 GPU days. On PASCAL VOC 2012 and ADE20K, our best model outper- forms several state-of-the-art models.
这篇论文将神经网络架构搜索运用在图像语义分割上。图像语义分割是计算即视觉方面的一个重要任务,目的是给图像中的每一个像素点都打上标签。
当前很多的NAS主要遵循一个两级的分层设计,但是只自动化搜索内部的核单元设计,至于外部的网络设计则采用人工设计。这篇论文提出了一个外部网络架构搜索空间,增加了研究较多的内部核单元搜索,并且进一步考虑了联合外部网络的搜索和内部核单元的搜索。
这篇论文也提出了一个可微分的连续方程,能够使两级分层架构能够在使用GPU的情况下3天完成任务。此外,根据这种方法得到模型在一些数据集上表现性能良好。
Related Work
Convolutional neural networks deployed in a fully convolutional manner (FCNs) have achieved remarkable performance on several semantic segmentation benchmarks. Within the state-of-the-art systems, there are two essential components: multi-scale context module and neural network design. In this work, we apply neural architecture search for network backbones specific for semantic segmentation. We further show state-of-the-art performance without ImageNet pretraining, and significantly outperforms FRRN and GridNet on Cityscapes.
Several papers used reinforcement learning (either policy gradients or Q-learning ) to train a recurrent neural network that represents a policy to generate a sequence of symbols specifying the CNN architecture. An alternative to RL is to use evolutionary algorithms (EA), that “evolves” architectures by mutating the best architectures found so far. These RL and EA methods tend to require massive computation during the search, usually thousands of GPU days. Our work follows the differentiable NAS formulation and extends it into the more general hierarchical setting.
Our work still uses this cell level search space to keep consistent with previous works. Yet one of our contributions is to propose a new, general-purpose network level search space, since we wish to jointly search across this two-level hierarchy.
把卷积神经网络运用到一个全卷积网络里,可以很好的解决语义分割的问题,但是要真正实现这个全卷积网络需要精心的设计和多范围数据的模块。这篇论文里将NAS用于解决这个问题,可以在不需要预训练的情况下获得一个很好的模型。
一些论文中使用强化学习来训练循环神经网络进而产生CNN架构的符号序列,一个强化学习的变体,进化算法也能通过”变异“来产生最终架构。这些方法在查找过程中都需要耗费大量的计算资源,而这篇论文则使用了可微分的NAS公式,并且将它推广到更通用的分层设置中,使得不必要挨个的训练模型,可以节省很多开销。
此外,这篇论文使用了之前工作中的核单位搜索空间,并加入了自己的贡献,即提出了一个新的,外在网络搜索空间,并且尽量通过两级分层结构将二者联合搜索。
Architecture Search Space
For the inner cell level , we reuse the one adopted in to keep consistent with previous works. For the outer network level , we propose a novel search space based on observation and summarization of many popular designs.
We define a cell to be a small fully convolutional module,typically repeated multiple times to form the entire neural network. More specifically, a cell is a directed acyclic graph consisting of B blocks.
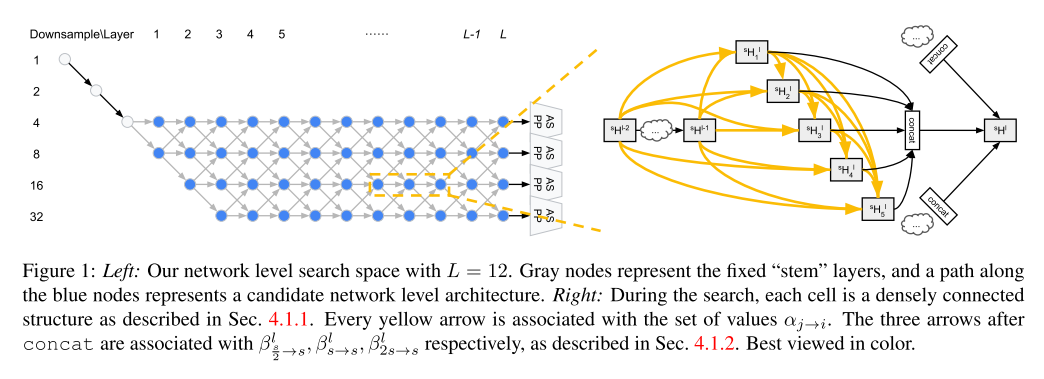
We propose the following network level search space. The beginning of the network is a two-layer “stem” structure that each reduces the spatial resolution by a factor of 2. After that, there are a total of L layers with unknown spatial resolutions, with the maximum being downsampled by 4 and the minimum being downsampled by 32. Since each layer may differ in spatial resolution by at most 2, the first layer after the stem could only be either downsampled by 4 or 8. We illustrate our network level search space in Fig. 1. Our goal is then to find a good path in this L-layer trellis.
这篇论文,在内部核单元搜索空间部分,重用了之前工作中的搜索空间,而在外部网络结构部分提出了一个新的基于对一些流行的设计的观察和总结而得出的搜索空间。
外部网络的搜索空间,这个网络的开始是一个两层的茎干部分,逐个减少两倍空间分辨率,在此之后是一个L层的未知空间分辨率,最大的是从4开始降采样,最小的是从32开始降采样。这个网络如图一所示,目标是在这个L层的格子里找到一个合适的路径。
Methods
The advantage of introducing this continuous relaxation is that the scalars controlling the connection strength between different hidden states are now part of the differentiable computation graph. Therefore they can be optimized efficiently using gradient descent. We adopt the first-order approximation and partition the training data into two disjoint sets trainA and trainB.
We decode the discrete cell architecture by first retaining the 2 strongest predecessors for each block , and then choose the most likely operator by taking the argmax.
Quite intuitively, our goal is to find the path with the “max- imum probability” from start to end. This path can be decoded efficiently using the classic Viterbi algorithm, as in our implementation.
这篇论文先通过公式将核架构和网络架构进行连续化操作,这样两层架构均变成了可微分的计算图,进而可以使用梯度下降的方法对其进行优化。针对核架构的解码,通过保留每一块最优的两个前置参数,并通过argmax选择最可能的运算符。针对外部网络架构的编码,目的是要找到一条从开始到结束的最大路径,这个路径可以使用经典的Viterbi算法编码。
Experimental Results
We consider a total of L = 12 layers in the network, and B = 5 blocks in a cell. The network level search space has 2.9 × 104 unique paths, and the number of cell structures is 5.6 × 1014. So the size of the joint, hierarchical search space is in the order of 1019. The architecture search optimization is conducted for a total of 40 epochs. The batch size is 2 due to GPU mem- ory constraint. When learning network weights w, we use SGD optimizer with momentum 0.9, cosine learning rate that decays from 0.025 to 0.001, and weight decay 0.0003. The initial values of α, β before softmax are sampled from a standard Gaussian times 0.001. They are optimized using Adam optimizer [36] with learning rate 0.003 and weight decay 0.001.
On Cityscapes, Auto-DeepLab significantly outperforms the previous state-of-the-art by 8.6%, and per- forms comparably with ImageNet-pretrained top models when exploiting the coarse annotations. On PASCAL VOC 2012 and ADE20K, Auto-DeepLab also outperforms several ImageNet-pretrained state-of-the-art models.
将NAS使用在语义分割上,经过在不同数据集上的实验,可以得到:在Cityscapes数据集上,auto-deepLab 明显的比其他一些经过ImageNet预训练的先进的方法表现良好,而且和经过ImageNet预训练的顶级模型相比性能差不多;在PASCAL VOC2012和ADE20K的数据集上,auto-deepLab和一部分经过ImageNet预训练的先进模型效果差不多,但表现效果并不是最好的。
Conclusion
For future work, within the current framework, related applications such as object detection should be plausible; we could also try untying the cell architecture α across different layers with little computation overhead. Beyond the current framework, a more general network level search space should be beneficial.
这种将核架构搜索和外部网络架构搜索一同使用的NAS是一个较好的发展方向,未来也可以应用于其他相关领域,比如物体检测。此外也可以从减少计算资源的角度着手,这样可以使得NAS有更广泛的应用场景。
Learning Transferable Architecture for Scalable Image Recognition
Zoph, B., Vasudevan, V., Shlens, J., & Le, Q. V. (2018). Learning Transferable Architectures for Scalable Image Recognition. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 8697–8710. https://doi.org/10.1109/CVPR.2018.00907
Introduction
In this paper, we study a new paradigm of designing convolutional architectures and describe a scalable method to optimize convolutional architectures on a dataset of interest, for instance the ImageNet classification dataset. We design a search space (which we call “the NASNet search space”) so that the complexity of the architecture is independent of the depth of the network and the size of input images. Our main result is that the best architecture found on CIFAR-10, called NASNet. The image features learned by NASNets are generically useful and transfer to other computer vision problems.
这篇论文提出了一种新的设计卷积网络架构的方法,并且优化了一些基于数据集的网络架构,设计了一个搜索空间,这个搜索空间被称为NASNet搜索空间。这种搜索空间使网络架构的复杂度独立于网络的深度和输入图片的大小。另外,这篇论文的主要成果就是在CIFAR-10数据集上得到的最优架构,即NASNet。从NASNet中提取出的图片特征一般均能转移到其他的计算机视觉问题。
Related Work
The proposed method is related to previous work in hyperparameter optimization. The design of our search space took much inspiration from LSTMs, and Neural Architecture Search Cell.
这篇论文和之前的一些超参数优化的工作相关,搜素空间的设计则来源于LSTM和NAS单元。
Method
The main contribution of this work is the design of a novel search space, such that the best architecture found on the CIFAR-10 dataset would scale to larger, higher- resolution image datasets across a range of computational settings.
In our approach, the overall architectures of the convolutional nets are manually predetermined. They are composed of convolutional cells repeated many times where each convolutional cell has the same architecture, but different weights. To easily build scalable architectures for images of any size, we need two types of convolutional cells to serve two main functions when taking in a feature map as input: (1) convolutional cells that return a feature map of the same dimension, and (2) convolutional cells that return a feature map where the feature map height and width is reduced by a factor of two. We name the first type and second type of convolutional cells Normal Cell and Reduction Cell respectively. The Reduction and Normal Cell could have the same architecture, but we empirically found it beneficial to learn two separate architectures.
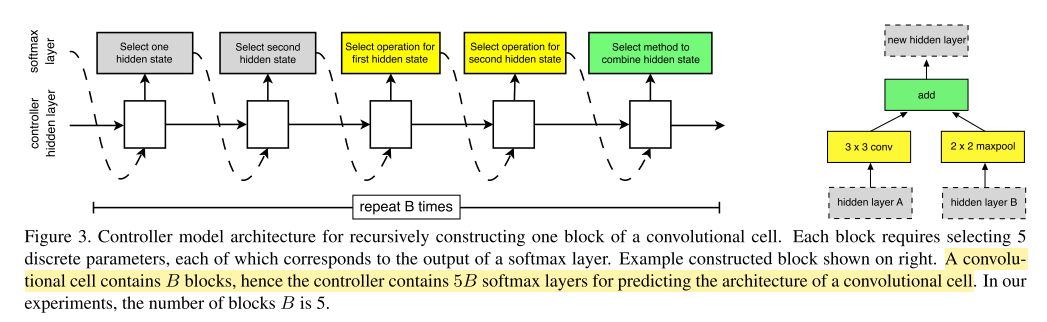
In our search space, each cell receives as input two initial hidden states hi and hi−1 which are the outputs of two cells in previous two lower layers or the input image. The controller RNN recursively predicts the rest of the structure of the convolutional cell, given these two initial hidden states(Figure 3).
在这篇论文的方法中,全部的卷积网络的架构是人工预先定义的,这些架构是由重复多次的卷积核组成,这些卷积核具有相同的结构和不同的权重。为了能够方便地构建针对任意大小图片的可拓展架构,这里提供了两种类型的卷积核,对于输入的特征图片分别对应不同的功能。一种能返回同样维度的特征图谱,称为Normal核;一种能够让特征图谱的宽高减半,称为Reduction核。这两种卷积核可以有同样的架构,但经过实验发现,不同的架构效果更好。
在搜索空间中,每一个卷积核以两个初始隐藏层状态作为两个输入参数,这两个参数要么是两个卷积核的输出,要么是输入的图像信息。控制器循环网络基于这两个参数递归预测卷积核剩下的结构。
Experiments and Results
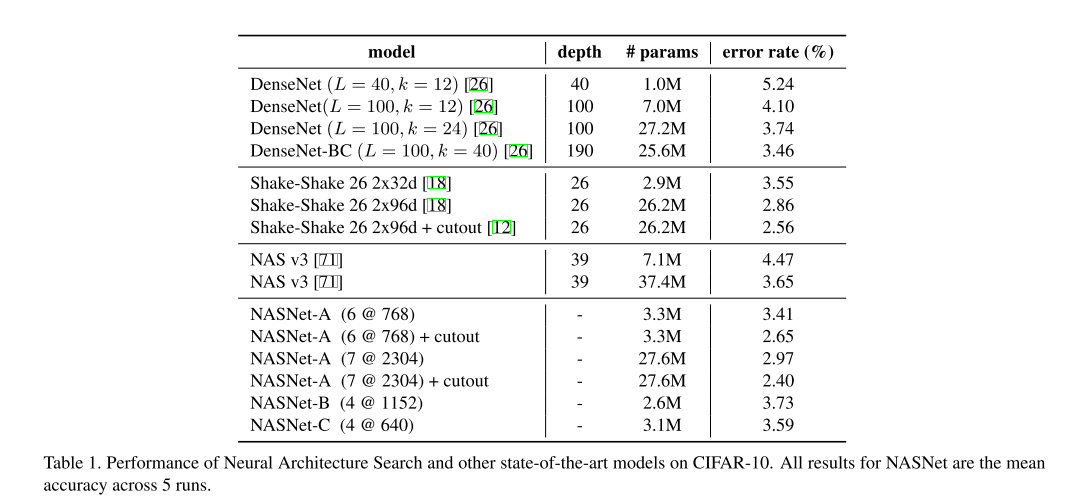
As can be seen from the Table 1, a large NASNet-A model with cutout data augmentation [12] achieves a state-of-the-art error rate of 2.40% (averaged across 5 runs), which is slightly better than the previous best record of 2.56% by [12].
We find that the learned convolutional cells are flexible across model scales achieving state-of-the-art performance across almost 2 orders of magnitude in computational budget.
Increasing the spatial resolution of the input image results in the best reported, single model result for object detection of 43.1%, surpassing the best previous best by over 4.0% . NASNet provides superior, generic image features that may be transferred across other computer vision tasks.
The best model identified with RL is significantly better than the best model found by RS by over 1% as measured by on CIFAR-10.
这篇论文在CIFAR-10和ImageNet数据集上进行了图像分类实验,得出的结果比之前的一些先进的方法略优一些。另外还将在ImageNet上预训练好的NASNet网络移入faster-rcnn框架进行了物体检测实验,数据集是COCO数据集,结果表现性能也不错,说明了这个架构可以迁移来解决到其他计算机视觉问题。最后还用实验说明了,使用强化学习(RL)进行架构搜索得到的模型结果比随机搜索(RS)得到的模型结果表现好。
Conclusion
The learned architecture is quite flexible as it may be scaled in terms of computational cost and parameters to easily address a variety of problems. The key insight in our approach is to design a search space that decouples the complexity of an architecture from the depth of a network.
we demonstrate that we can use the resulting learned architecture to perform ImageNet classification with reduced computational budgets that outperform streamlined architectures targeted to mobile and embedded platforms.
这篇论文提出的NASNet能够很灵活地可以扩展到计算机视觉的其他问题的解决上,而且NASNet搜索空间也将架构的复杂性与网络的深度分离开。
Random Search and Reproducibility for Neural Architecture Search
Li, L., & Talwalkar, A. (2019). Random Search and Reproducibility for Neural Architecture Search. 1–20. Retrieved from http://arxiv.org/abs/1902.07638
Introduction
We see three fundamental issues with the current state of NAS research: Inadequate Baselines. Complex Methods. Lack of Reproducibility.
We help ground existing NAS results by providing a new perspective on the gap between traditional hy- perparameter optimization and leading NAS methods.
We identify a small subset of NAS components that are sufficient for achieving good empirical results.
We open-source all of the necessary code, random seeds, and documentation necessary to reproduce our experiments.
这篇论文发现了现存的NAS研究里的三种基本的问题,分别是:基准不足,方法复杂,难以复现。
这篇论文的贡献是:在传统的超参数调优方法和先进的NAS方法的比较中提出了新的看法;从NAS组件中选出了一部分足以实现好的实验效果的子集;开源了必要的代码,随机种子和复现实验时所需文档。
Related Work
We choose to use a simple method combining random search with early-stopping called ASHA to provide a competitive baseline for standard hyperparameter optimization.
Our combination of random search with weight-sharing greatly simplifies the training routine and we identify key variables needed to achieve competitive results on both CIFAR-10 and PTB benchmarks.
We follow DARTS and report the result of our random weight-sharing method across multiple trials; in fact, we go one step further and evaluate the broad reproducibility of our results with multiple sets of random seeds.
在相关工作这一部分,这篇论文针对NAS研究里的三个问题分别列举了当前的一些研究工作,并给出了自己相应的解决方案。关于基准不足,这篇论文使用了结合早停的随机搜索的方法,这个方法给标准的超参数调优提供了一个有竞争力的基准;关于方法复杂,这篇论文使用了结合参数共享的随机搜索方法,进而简化了训练过程;关于难以复现,这篇论文给出了复现的相关文档和随机种子,并对结果的可复现性进行了评测。
Methodology
Our algorithm is designed for an arbitrary search space with a DAG representation, we use the same search spaces as that considered by DARTS [34] for the standard CIFAR-10 and PTB NAS benchmarks.
There are a few key meta-hyperparameters that impact the behavior of our search algorithm: Training epochs.Batch size.Network size.Number of evaluated architectures.
Since we train the shared weights using a single architecture at a time, we have the option of only loading the weights associated with the operations and edges that are activated into GPU memory. Hence, the memory footprint of our random search with weight-sharing can be reduced to that of a single model.
这篇论文的随机搜索算法使用的搜索空间和DARTS在CIFAR-10和PTB上使用的搜索空间相同。另外,有一些元超参数能够影响这篇论文的搜索算法,比如训练次数,分块大小,网络大小和评估架构的数量。最后,因为这篇论文在训练共享权重时每次只使用一个架构,所以每次只需要将和架构相关的权重和操作加载进GPU存储里就行,因此这里的结合权重共享的随机搜索算法能够节省GPU开销。
Experiments
To evaluate the performance of random search with weight-sharing on these two benchmarks, we proceed in the same three stages:
- Stage 1: Perform architecture search for a cell block on a cheaper search task.
- Stage 2: Evaluate the best architecture from the first stage by retraining a larger, network formed from multiple cell blocks of the best found architecture from scratch. This stage is used to select the best architecture from multiple trials.
- Stage 3: Perform the full evaluation of the best found architecture from the second stage by either training for more epochs (PTB) or training with more seeds (CIFAR-10).
For the PTB benchmark, we refer to the network used in the first stage as the proxy network and the network in the later stages as the proxyless network. We next present the final search results. We subsequently explore the impact of various meta-hyperparameters on random search with weight-sharing, and finally evaluate the reproducibility of various methods on this benchmark. Comparison with state-of-the-art NAS methods and manually designednetworks. Lower test perplexity is better on this benchmark.
For the CIFAR-10 benchmark,the DAG considered for the convolutional cell has N = 4 search nodes and the operations considered include 3 × 3 and 5 × 5 separable convolutions, 3 × 3 and 5 × 5 dilated separable convolutions, 3 × 3 max pooling, and 3 × 3 average pooling, and zero.Comparison with state-of-the-art NAS methods and manually designed networks.
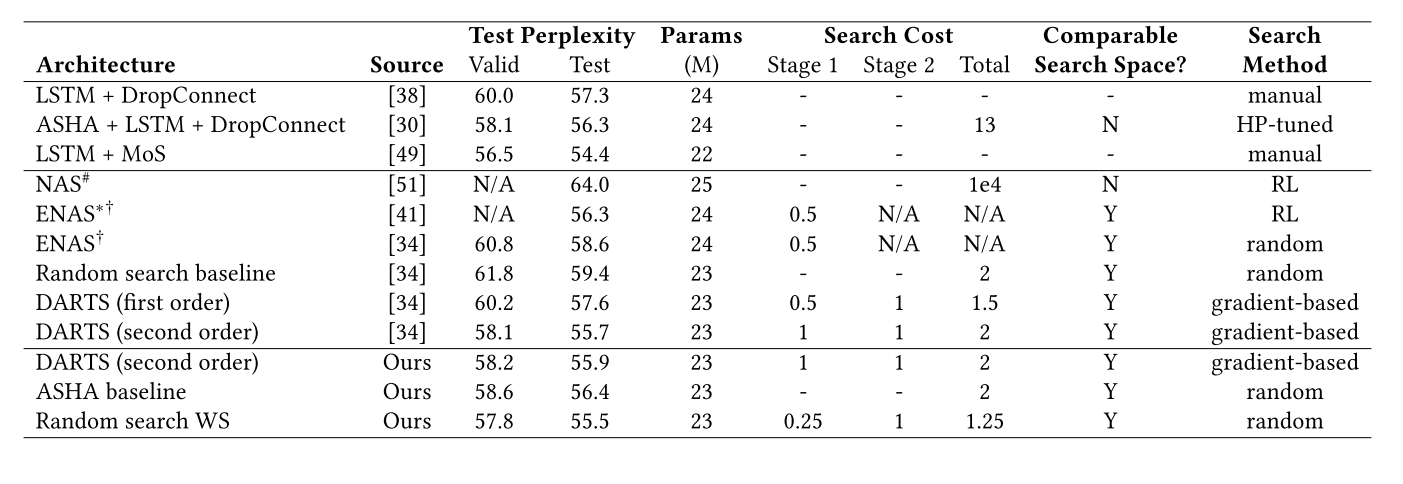
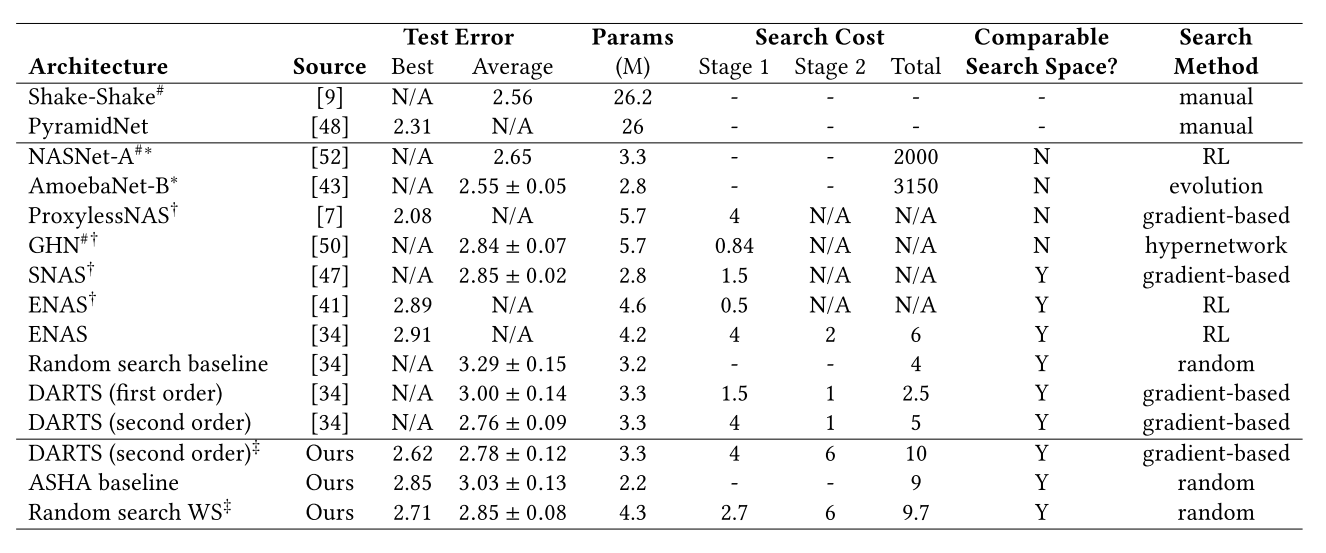
为了评估在在PTB和CIFAR-10两个基准上权重共享的随机搜索的性能,这篇论文进行了相同的三个阶段:
- 阶段1:在一个资源耗费较少的搜索任务上对一个单元格块执行架构搜索。
- 阶段2:通过重新训练一个更大的网络来评估第一个阶段的最佳架构,这个网络由多个单元块组成,这些单元块是从零开始找到的最佳架构。这个阶段用于从多个测试中选择最佳架构。
- 阶段3:对第二阶段发现的最佳体系结构进行全面评估,方法是进行更多epoch (PTB)的训练,或者进行更多seed (CIFAR-10)的训练。
对在两个基准上分别进行上述三个阶段的操作,最终对比一些已有的NAS方法和人工调参,得到上述两个对比表,可以看出,在PTB基准上能够得到比其他方法较小的perplexity,而在CIFAR-10基准上能够得到相对较少的errors。
Conclusion
Better baselines that accurately quantify the performance gains of NAS methods.
Ablation studies that isolate the impact of individual NAS components.
Reproducible results that engender confidence and foster scientific progress.
这篇论文成果有,提出了一个基本的基准(即论文中随机搜索的方法)来准确地衡量NAS方法的性能收益;对多个NAS组件的影响进行了探索;使NAS实验结果可复现,推动了科研进程。
DARTS: DIFFERENTIABLE ARCHITECTURE SEARCH
Liu, H., Simonyan, K., & Yang, Y. (2018). DARTS: Differentiable Architecture Search. 1–13. Retrieved from http://arxiv.org/abs/1806.09055
Introduction
The best existing architecture search algorithms are computationally demanding despite their remark- able performance.In this work, we approach the problem from a different angle, and propose a method for efficient architecture search called DARTS (Differentiable ARchiTecture Search).Instead of searching over a discrete set of candidate architectures, we relax the search space to be continuous, so that the architecture can be optimized with respect to its validation set performance by gradient descent.
现有的最佳体系结构搜索算法尽管具有可评注的性能,但在计算上要求很高。这篇论文从不同的角度来解决这个问题,并提出了一种有效的架构搜索方法,称为可微架构搜索DARTS。这篇论文没有在一组离散的候选架构上进行搜索,而是将搜索空间放宽为连续的,这样就可以通过梯度下降对架构的验证集性能进行优化,进而提高计算效率。
Differentiable Architecture Search
We search for a computation cell as the building block of the final architecture. The learned cell could either be stacked to form a convolutional network or recursively connected to form a recurrent network.
To make the search space continuous, we relax the categorical choice of a particular operation to a softmax over all possible operations. After relaxation, our goal is to jointly learn the architecture α and the weights w within all the mixed operations.
这篇论文用一个计算单元作为最终架构的构建块。这个学习单元可以堆叠成卷积网络,也可以递归连接成递归网络。为了使搜索空间连续,这篇论文将特定操作的分类选择放宽到所有可能操作的softmax,之后联合学习架构α和权重w。
Experiments and Results
Our experiments on CIFAR-10 and PTB consist of two stages, architecture search and architecture evaluation. In the first stage, we search for the cell architectures using DARTS, and determine the best cells based on their validation performance. In the second stage, we use these cells to construct larger architectures, which we train from scratch and report their performance on the test set. We also investigate the transferability of the best cells learned on CIFAR-10 and PTB by evaluating them on ImageNet and WikiText-2 (WT2) respectively.
DARTS achieved comparable results with the state of the art (Zoph et al., 2018; Real et al., 2018) while using three orders of magnitude less computation resources.
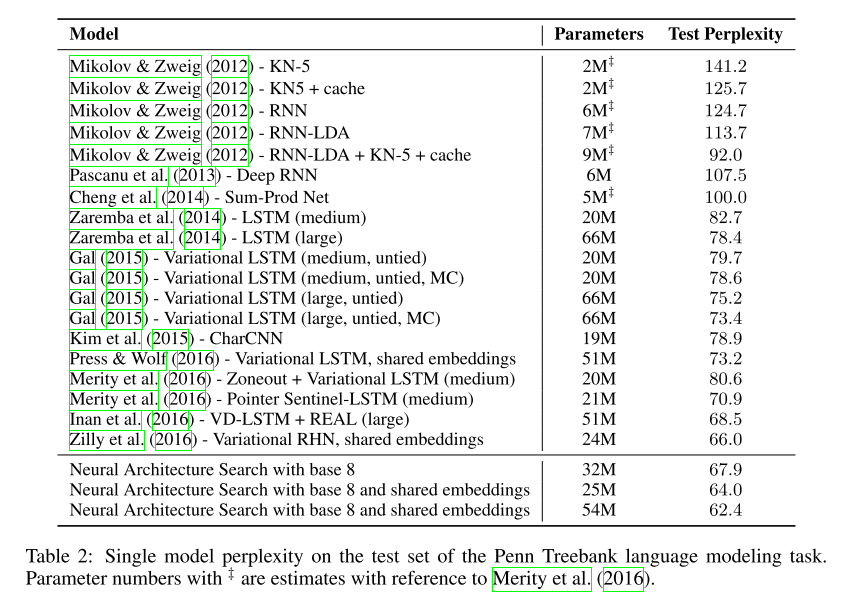
Table 2 presents the results for recurrent architectures on PTB, where a cell discovered by DARTS achieved the test perplexity of 55.7. This is on par with the state-of-the-art model enhanced by a mixture of softmaxes (Yang et al., 2018), and better than all the rest of the architectures that are either manually or automatically discovered.
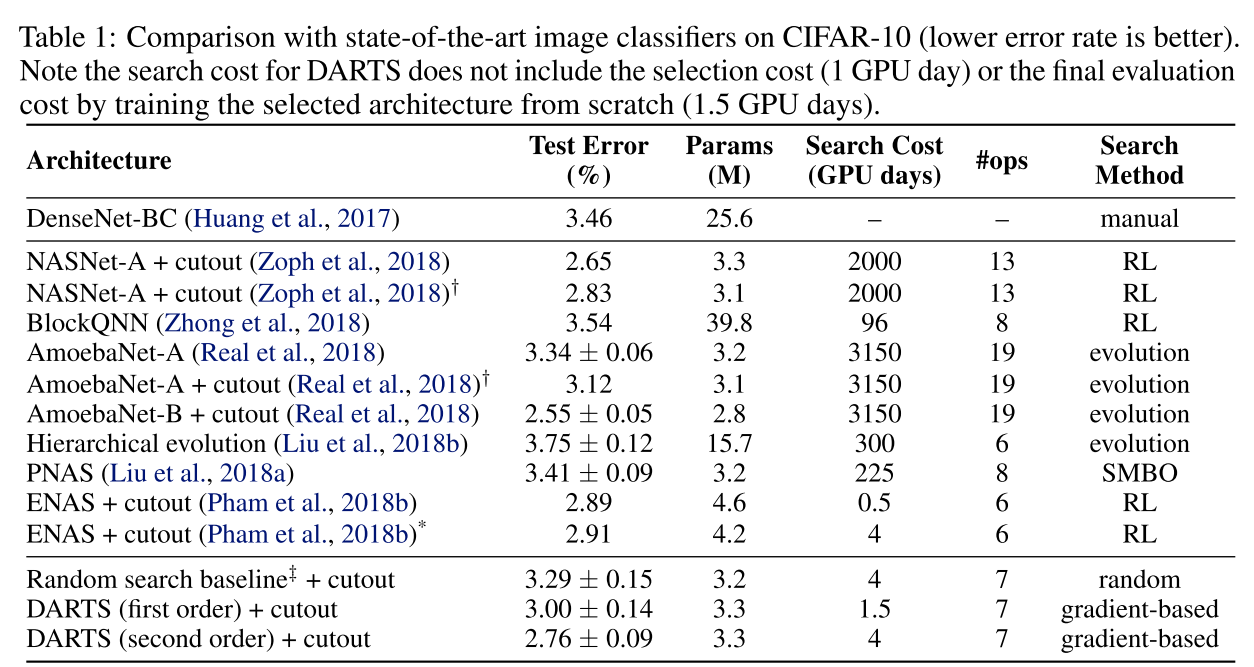
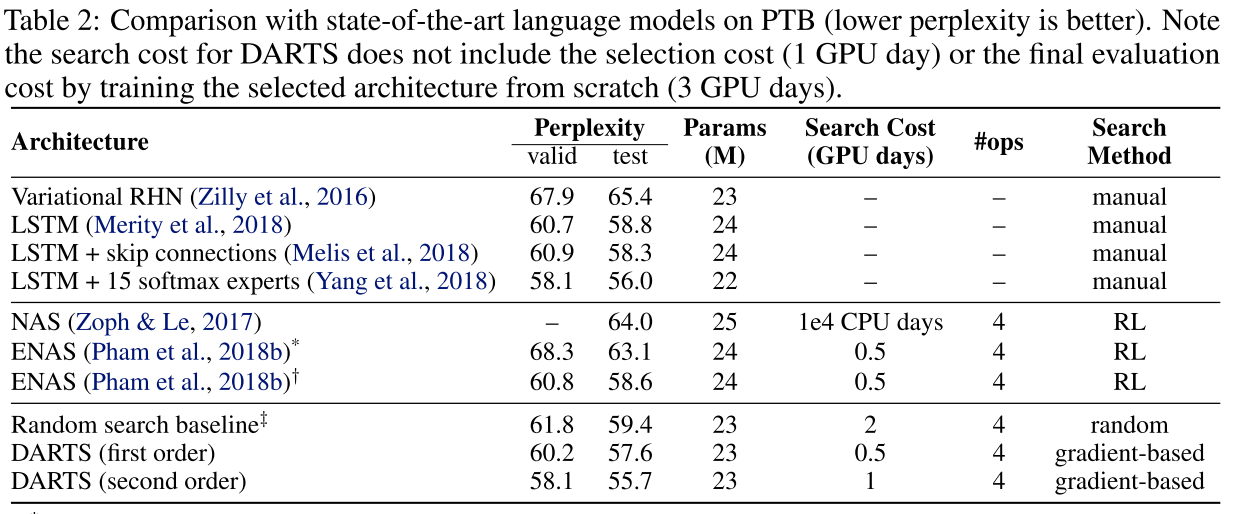
这篇论文在CIFAR-10和PTB上的实验分为架构搜索和架构评估两个阶段。
在第一个阶段,使用DARTS搜索单元结构,并根据它们的验证性能确定最佳单元。
在第二阶段中,使用这些单元来构建更大的架构,从头开始训练并报告他们在测试集上的表现。
另外,这篇论文也调查的最佳单元的可转让性,并评估这个单元在ImageNet和WikiText-2 (WT2)上的性能。
Conclusion
We presented DARTS, a simple yet efficient architecture search algorithm for both convolutional and recurrent networks. By searching in a continuous space, DARTS is able to match or outperform the state-of-the-art non-differentiable architecture search methods on image classification and language modeling tasks with remarkable efficiency improvement by several orders of magnitude.
这篇论文提出了一种简单而有效的卷积和递归网络结构搜索算法DARTS。通过在连续空间中搜索,DARTS能够在图像分类和语言建模任务上匹配或优于目前最先进的不可微架构搜索方法,效率显著提高了几个数量级。