Auto Machine Learning Survey Notes(Ⅰ)
Paper Name:
Yao, Q., Wang, M., Chen, Y., Dai, W., Yi-Qi, H., Yu-Feng, L., … Yang, Y. (2018). Taking Human out of Learning Applications: A Survey on Automated Machine Learning. 1–26. Retrieved from http://arxiv.org/abs/1810.13306
First Section
In first section,this paper first explains why we need to investigate AutoML. Its reason is following. Machine Learning has been popular recently , but every aspect of machine learning applications, such as feature engineering, model selection, and algorithm selection, needs to be carefully configured, which costs the efforts of many human experts. So we need to research AutoML to take human out of Learning Application and give experts more time to analyze data and problem,and finally promote the development of Machine Learning. This paper also gives some examples of automated machine learning in industry and academic, like Auto-sklearn, Google’s cloud autoML , and Feature Labs, which shows that AutoML has already been successfully applied in many important problems.
在第一部分中,本文首先解释了为什么我们需要研究AutoML。 因为机器学习近些年很流行,但机器学习应用的各个方面,如特征工程,模型选择和算法选择,都需要仔细配置,这需要许多专业人士的努力。所以我们需要研究AutoML以使人类能够从模型训练中解放出来,能够集中精力分析数据和问题本身,最终促进机器学习的发展。 本文还提供了一些工业和学术界自动化机器学习的例子,如Auto-sklearn,Google的 Cloud AutoML,还有Feature Labs,它们表明了AutoML已成功应用于许多重要问题。
Second Section
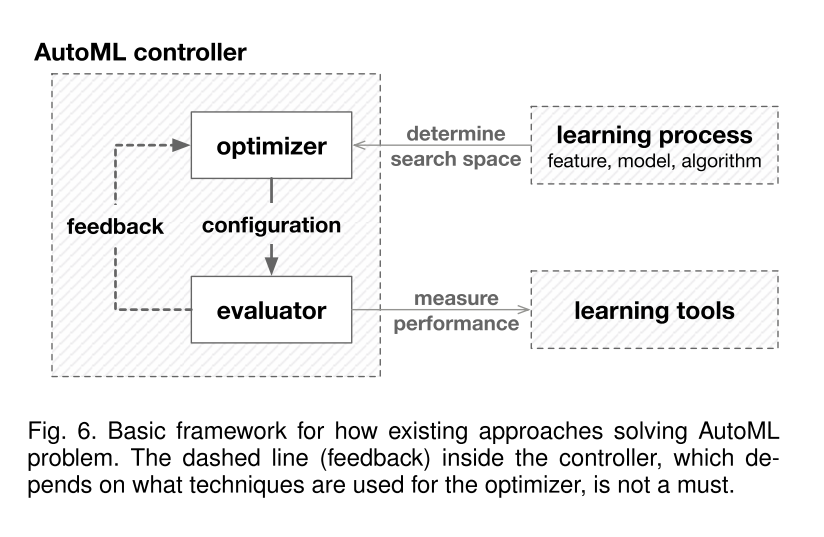
In second section, this paper firstly defines AutoML and its core goal. AutoML attempts to construct machine learning programs(specified by Experience, Task and Performance ),without human assitance and within limited computational budgets. And its three core goals are good performance , no assistance from humans and high computational efficiency. Next, this paper propose a basic framework for AutoML approaches. In this framework, an AutoML controller, which has two key ingredients,the optimizer and the evaluator, takes the place of human to find proper configurations for the learning tools. The duty of the evaluator is to measure the performance of the learning tools with configurations provided by the optimizer , while the optimizer’s duty is to update or generate configurations for learning tools. Finally, this paper shows AutoML approaches taxonomies by problem setup and techniques.
在第二部分中,本文首先定义了AutoML及其核心目标。 AutoML尝试构建机器学习程序(由经验,任务和性能指定),无需人工协助并且在有限的计算预算内。 它的三个核心目标是良好的性能,没有人类的帮助和高计算效率。 接下来,本文提出了AutoML方法的基本框架。 在这个框架中,AutoML控制器取代了人类的工作,为学习方法找到合适的配置方式,这个控制器有两个关键组成部分,即优化器和评估器。 在本节的最后,本文将AutoML的方法分为问题设置和技术处理两类。
Third Section
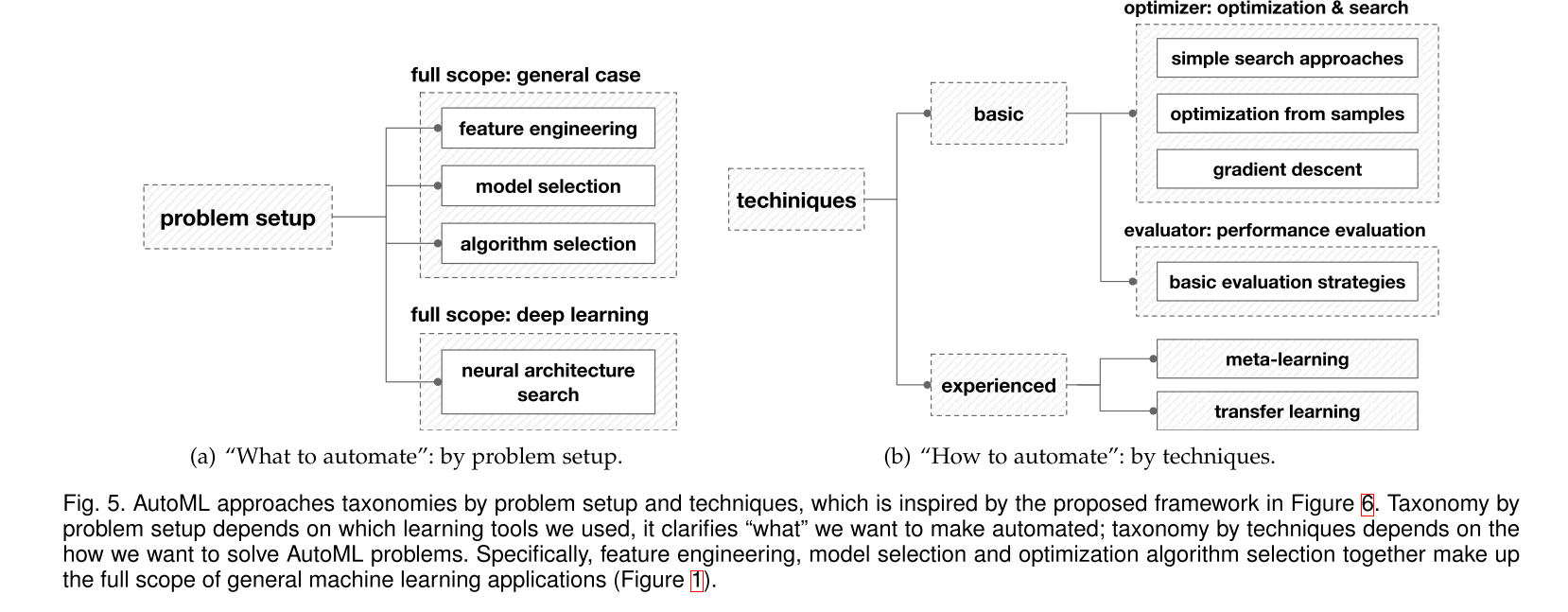
In third section, this paper gives details on problem setup and introduces some existing AutoML approaches on learning process. AutoML approaches do not necessarily cover the full machine learning pipeline, they can also focus on some parts of the learning process.
As for some parts of the learning process, AutoML approaches includes feature engineering , model selection, and optimization algorithm selection.
Feature engineering is to automatically construct features from the data so that subsequent learning tools can have good performance. This goal can be divided into two sub-problems. creating features from the data and enhance features’ discriminative ability. However, there are no common or principled methods to create features from data. So , now AutoML focus on feature enhancing methods and there are some common methods to enhance features, dimension reduction,feature generation and feature encoding.
Models selection contains two components, picking up some classifiers and setting their corresponding hyper-parameters. The task of model selection is to automatically select classifiers and set their hyper-parameters so that good learning performance can be contained.
The goal of optimization algorithm selection is to automatically find an optimization algorithm so that efficiency and performance can be balanced.
What’s more, in this section, this paper give two classes of full-scope AutoML approaches. The first one is general case, which is a combination of feature engineering, model selection and algorithm selection. The second one is Network Architecture Search (NAS), which targets at searching good deep network architectures that suit the learning problem.
在第三部分中,本文详细介绍了问题的设置,并介绍了一些现有的AutoML的方法。AutoML可以不必覆盖机器学习的全范围,仅专注于学习过程中的一部分。
针对机器学习的某些部分,AutoML的方法可分为特征工程,模型选择和优化算法选择。特征工程是从数据中自动构造特征,以便后续学习工具可以具有良好的性能。这个目标可以分为两个子问题,一个是从数据创建功能,另一个是增强功能的辨别能力。但是,没有通用或原则方法从数据创建功能。因此,现在AutoML专注于特征增强方法,并且有一些常用方法可以增强特征,例如降维,特征生成和特征编码。模型选择包含两个组成部分,分别是选取分类器和设置其相应的超参数。模型选择的任务是自动选择分类器并设置其超参数,以便可以包含良好的学习性能。优化算法选择的目标是自动找到优化算法,以便平衡效率和性能。
此外,在本节中,本文提供了两类全范围AutoML方法。第一个是一般情况,它是特征工程,模型选择和算法选择的组合。第二个是网络架构搜索(NAS),其目标是搜索适合学习问题的良好深度网络架构。
Fourth Section
In fourth section, this paper introduces some basic techniques for optimizer. It has three parts including simple search approaches, optimization from samples and gradient descent. Simple search is a naive search approach, and grid search and random search are two common approaches.
Optimization from samples is a kind of smarter search approach, and this paper divide existing approaches into three categories, heuristic search, model-based derivative-free optimization, and reinforcement learning. Some popular heuristic search methods are Particle swarm optimization(PSO), Evolutionary Algorithms. The popular methods of model-based derivative-free optimization are Bayesian optimization, classification-based optimization (CBO) and simultaneous optimistic optimization (SOO) . Reinforcement learning (RL) is a very general and strong optimization framework, which can solve problems with delayed feedbacks.
Greedy search is a natural strategy to solve multi-step decision-making problem.
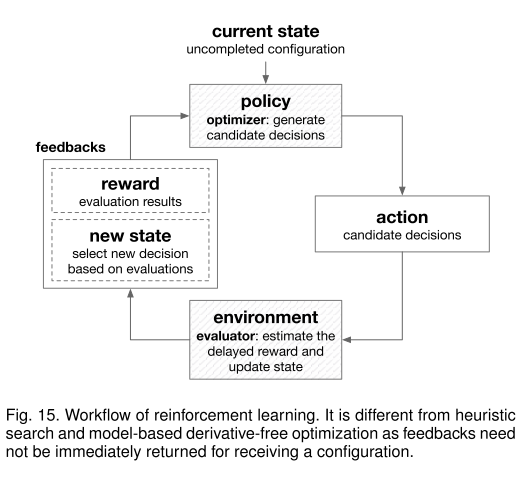
在第四部分中,本文介绍了优化器的一些基本技术。 它有三个部分,包括简单搜索方法,样本优化和梯度下降。 简单搜索是一种朴素的搜索方法,其中两种常见的方法分别是网格搜索和随机搜索。样本优化是一种更智能的搜索方法,本文将现有的相关方法分为三类:启发式搜索,基于模型的无导数优化和强化学习。 一些流行的启发式搜索方法是粒子群优化(PSO),进化算法。 基于模型的无导数优化的流行方法是贝叶斯优化,基于分类的优化(CBO)和同时优化优化(SOO)。 强化学习(RL)是一个非常通用且强大的优化框架,可以解决延迟反馈的问题。此外,贪心搜索是解决多步决策问题的常用策略。
Fifth Section
In fifth section, this paper introduce some basic techniques for evaluator. And the existing methods are direct evaluation, sub-sampling, early stop, parameter reusing and surrogate evaluator. Direct evaluation is often accurate but expensive, and some other methods have been proposed for acceleration by trading evaluation accuracy for efficiency.
在第五部分,本文介绍了评估器的一些基本技术。 现有的方法有直接评估,子抽样,早期停止,参数重用和代理评估。 直接评估通常是准确的但效率不高,而其他的方法是来通过降低评估准确性来提高效率。
Sixth Section
In sixth section, this paper introduce some experienced techniques , there are two main topics, meta-learning and transfer learning.
Meta-learning helps AutoML, on the one hand, by characterizing learning problems and tools.,on the other hand, the meta-learner encodes past experience and acts as a guidance to solve future problems.
Existing meta-learning techniques by categorizing them into three general classes based on their applications in AutoML are following:
- meta-learning for configuration evaluation (for the evaluator). Meta-learners can be trained as surrogate evaluators to predict performances, applicabilities, or ranking of configurations. Representative applications of meta-learning in configuration evaluation are Model evaluation and General configuration evaluation.
- meta- learning for configuration generation (for the optimizer). The approaches have promising configuration generation, warming-starting configuration generation , and search space refining.
- meta-learning for dynamic configuration adaptation. Meta-learning can help to automate this procedure by detecting concept drift and dynamically adapting learning
drift.
Transfer learning tries to improve the learning on target domain and learning task, by using the knowledge from the source domain and learning task.
Transfer learning has been exploited to reuse trained surrogate models or promising search strategies from past AutoML search (source) and improve the efficiency in current AutoML task (target). By transferring knowledge from previous configuration evaluations, we can avoid training model from scratch for the upcoming evaluations and significantly improve the efficiency.
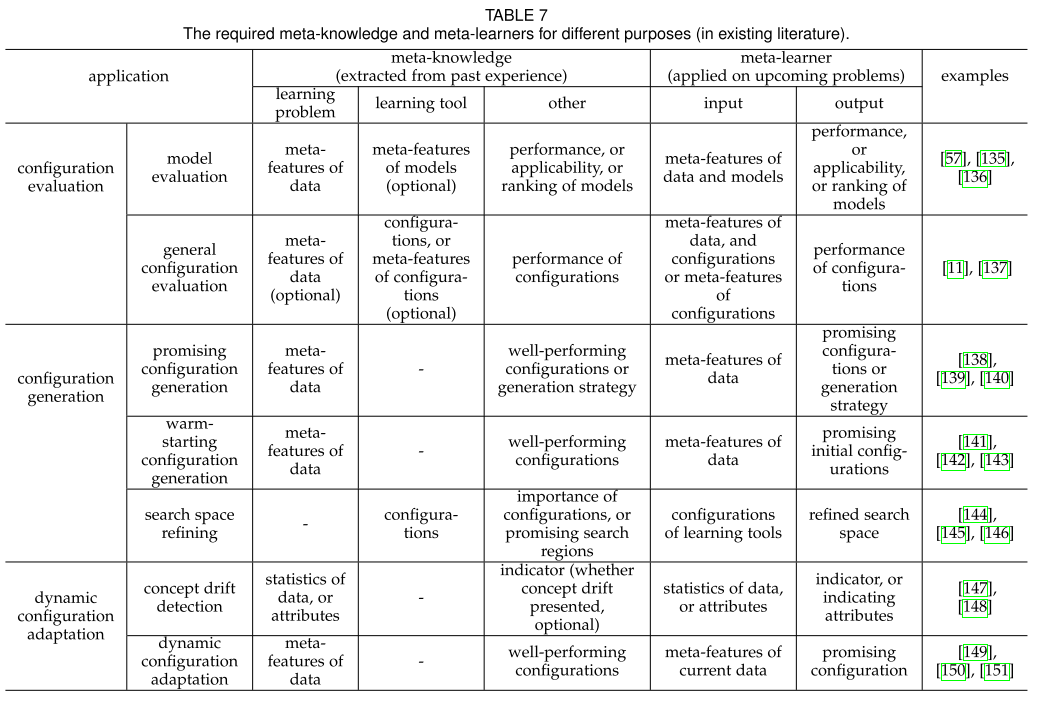
在第六部分,本文介绍了一些比较先进的技术,主要有两个主题,元学习和迁移学习。
元学习辅助AutoML,一方面通过对学习问题和工具的表征。另一方面,通过编码以往的经验来作为对解决未来问题的指导。
基于AutoML中的应用程序,将现有的元学习技术分为三个通用类:
1.用于配置评估的元学习(用于评估器)。元学习器可以作为代理评估器进行训练,以预测性能,适用性或配置排名。元学习在配置评估中的代表性应用有模型评估和一般配置评估这两种。
2.用于配置生成的元学习(用于优化器)。相关方法有:良好配置生成,预热配置生成和搜索空间精炼。
3.动态配置适应的元学习。元学习可以通过检测概念转换和动态调整学习转换来帮助AutoML。迁移学习通过使用来自源域和学习任务的知识,尝试改进对目标域和学习任务的学习。
迁移学习能重用过去AutoML任务(源)经过训练的代理模型或优良的搜索策略,并提高当前AutoML任务(目标)的效率。通过从以前的配置评估中迁移知识,可以避免从头训练模型,显著提高效率。
Seventh Section
In seventh section, this paper introduce three AutoML examples, Auto-sklearn, NASNet and ExploreKit.
In Auto-sklearn, model selection is formulated as a CASH problem, which aims to minimize the validation loss with respect to the model as well as its hyper-parameters and parameters.
RL is employed in NAS to search for a optimal sequence of design decisions. Besides, the direct evaluation is used in these works as the evaluator. As RL is slow to converge, to make the search faster, transfer learning, which is firstly used to cut the search space into several blocks.
ExploreKit conducts more expensive and accurate evaluations on the candidate features. Error reduction on the validation set is used as the metric for feature importance. Candidate features are evaluated successively according to their ranking, and selected if their usefulness surpass a threshold. This procedure terminates if enough improvement is achieved. The selected features will be used to generate new candidates in the following iterations.
在第七部分中,本文介绍了三个AutoML应用示例,Auto-sklearn,NASNet和ExploreKit。
在Auto-sklearn中,模型选择被公式化为CASH问题,其目的是最小化模型的验证损失函数及其超参数和参数。
NAS使用RL来搜索最佳的设计决策序列,使用直接评估作为整个工作的评估器。但RL收敛缓慢,为了使搜索更快,NAS使用了转移学习,在搜索之前将搜索空间切割成几个块,以加快收敛速度。
ExploreKit对候选功能进行更准确但更低效的评估。将验证集上的错误减少情况用作特征有效性的度量标准,按照相应排名对候选特征进行评估,并选择有效性超过阈值的特征,所选的特征将在以下的迭代中生成新候选。如果实现了足够的效果,则迭代过程终止。
Eighth Section
In eighth section, this paper reviews the history of AutoML, summarizes how its current status in the academy and industry, and discuss its future work.
AutoML only becomes practical and a big focus recently, due to the big data, the increasing computation of modern computers, and of course, the great demand of machine learning application.
AutoML is a very complex problem and also an extremely active research area, and there are many new opportunities and problems in AutoML. And there are also many workshops and competitions.
Higher efficiency can be achieved by either proposing algorithms for the optimizer, which visit less configurations before reaching a good performance, or designing better methods for the evaluator, which can offer more accurate evaluations but in less time.
在第八部分,本文回顾了AutoML的历史,总结了其在学术界和行业中的现状,并讨论了其未来的发展方向。
由于大数据,现代计算机的计算量不断增加,当然还有机器学习应用的巨大需求,AutoML最近才成为重点。
AutoML是一个非常复杂的问题,也是一个非常活跃的研究领域,AutoML中存在许多新的机会和问题,还有许多研讨会和比赛。
为优化器提出算法可以实现更高的效率,这样使得优化器在达到良好性能之前访问较少的配置;或者为评估器设计更好的方法,这可以在更短的时间内提供更准确的评估。
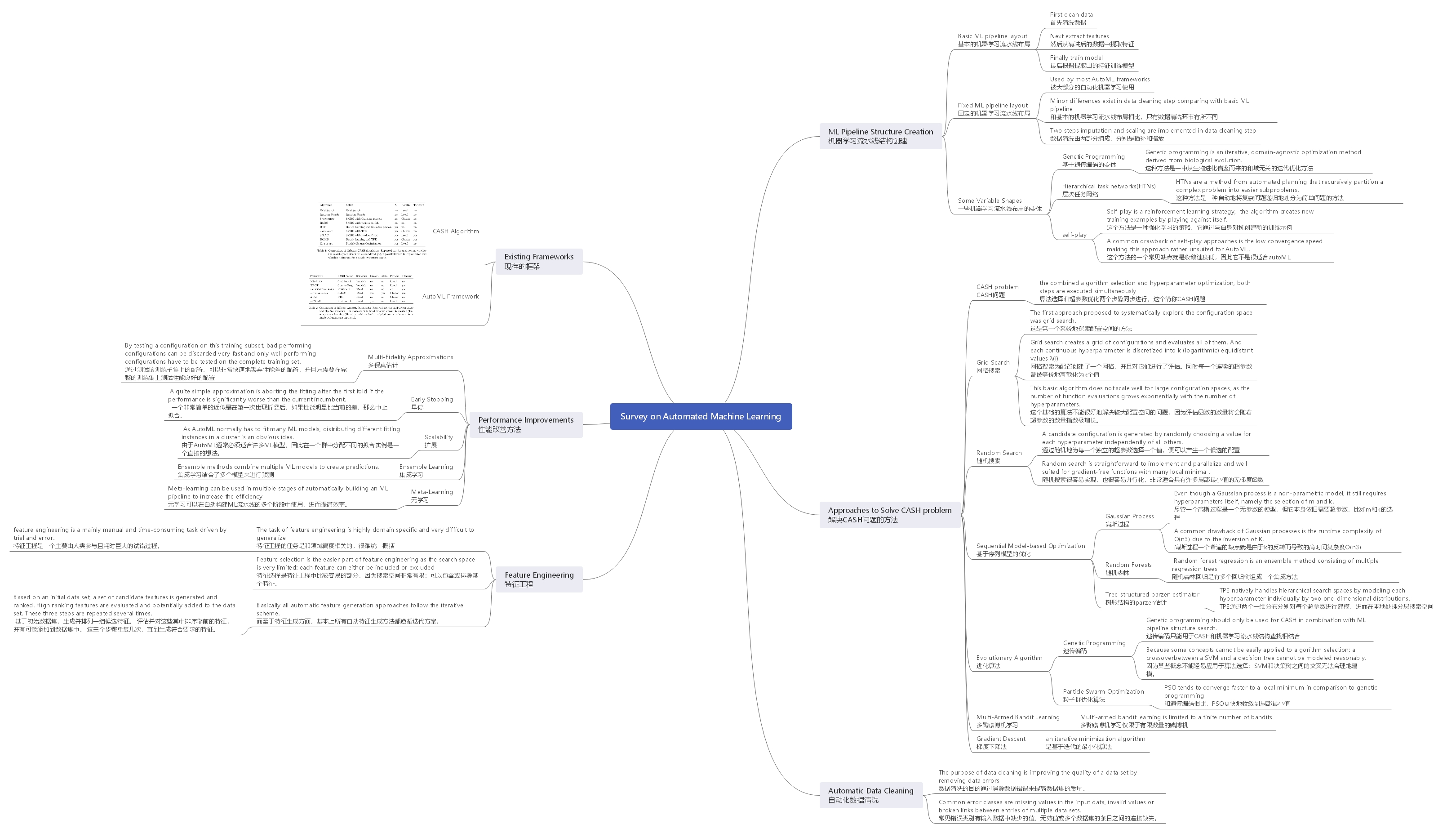
Appendix Ⅰ : This Survey Mindmap
Auto Machine Learning Survey Notes(Ⅱ)
Elshawi, R., Maher, M., & Sakr, S. (2019). Automated Machine Learning: State-of-The-Art and Open Challenges. Retrieved from http://arxiv.org/abs/1906.02287
First Section
In first section, this paper briefly introduces the development of AutoML and explain what is the CASH (Combined Algorithm Selection and Hyper-parameter tuning) problem.
在第一部分中,本文简要介绍了AutoML的发展,并解释了什么是CASH问题。
Second Section
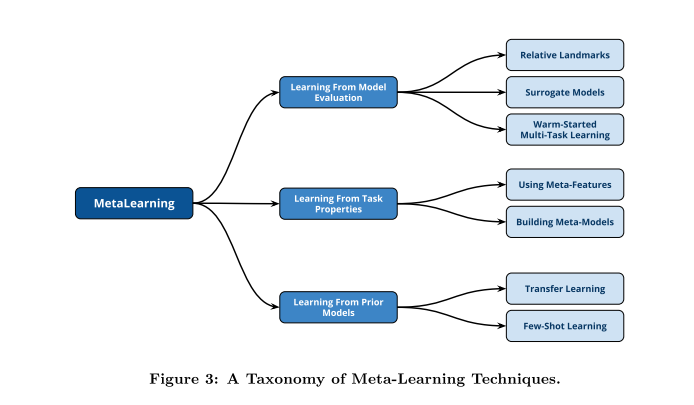
In Second section, this paper introduces the various techniques that have been introduced to tackle the challenge of warm starting(meta-learning) for AutoML search problem in the context of machine learning and deep learning domains.. These techniques can generally be categorized into three broad groups: learning based on task properties, learning from previous model evaluations and learning from already pretrained models.
在第二部分中,本文介绍了在机器学习和深度学习领域中针对AutoML搜索问题的热启动(元学习)挑战所引入的各种技术。 这些技术通常可以分为三大类:从任务属性中学习,从先前模型评估中学习以及从已经预训练的模型中学习。
Third Section
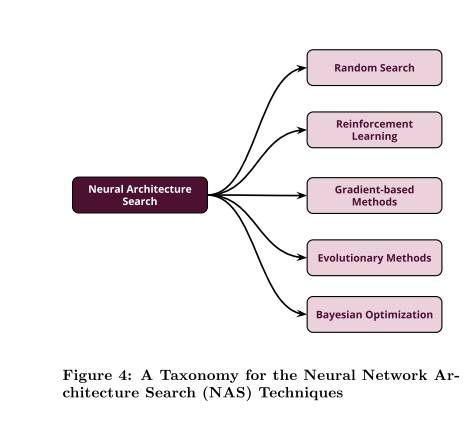
In third section, this paper introduces the various approaches that have been introduced for tackling the challenge of neural architecture search(NAS) in the context of deep learning. Broadly, NAS techniques falls into five main categories including random search, reinforcement learning, gradient- based methods, evolutionary methods, and Bayesian optimization.
在第三部分中,本文介绍了在深度学习环境中应对神经结构搜索(NAS)挑战的各种方法。 从广义上讲,NAS技术分为五大类,包括随机搜索,强化学习,基于梯度的方法,进化方法和贝叶斯优化。
Fourth Section
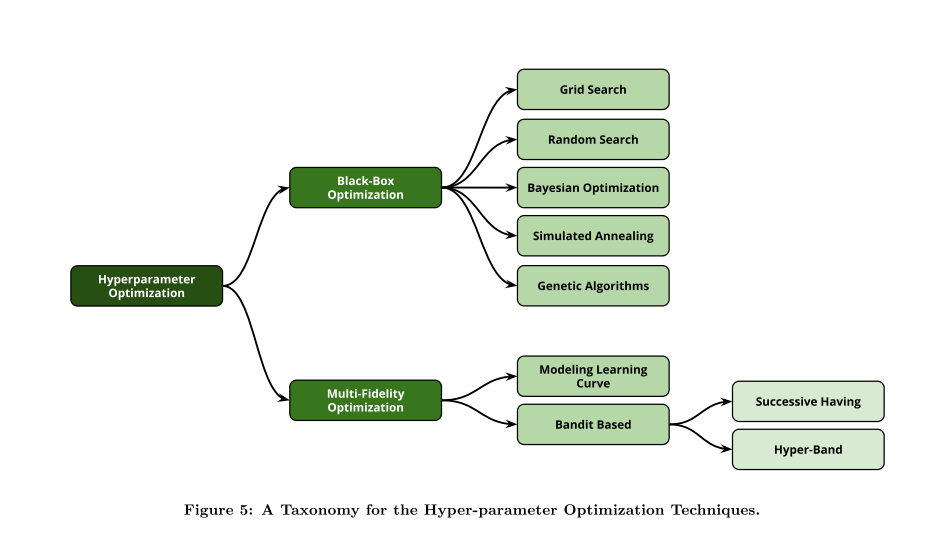
In fourth section, this paper introduces some different approaches for automated hyper-parameter optimization. In principle, the automated hyper-parameter tuning techniques can be classified into two main categories: black-box optimization techniques and multi-fidelity optimization techniques.
在第四部分中,本文介绍了一些不同的自动超参数优化的方法。 原则上,自动超参数调整技术可以分为两大类:黑盒优化技术和多保真优化技术。
Fifth Section
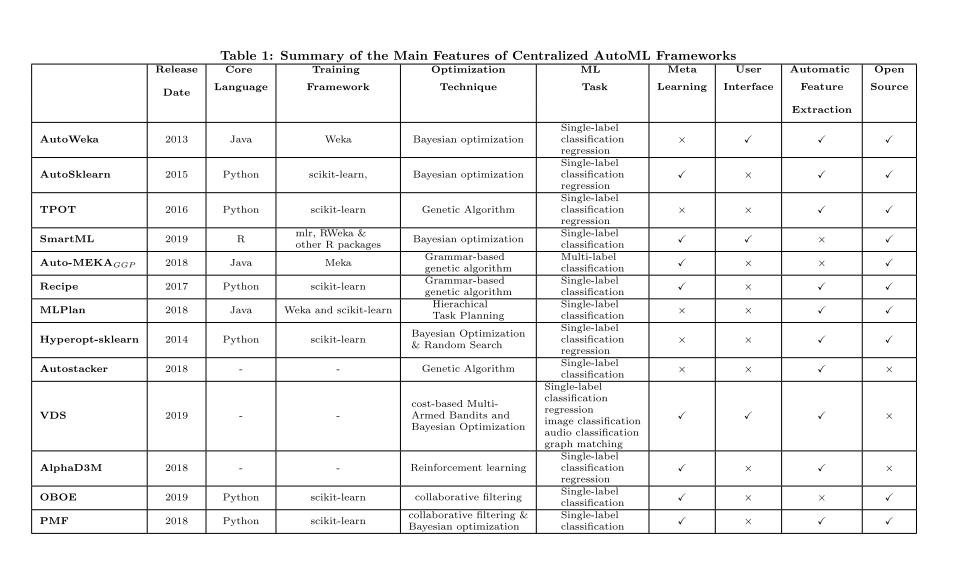
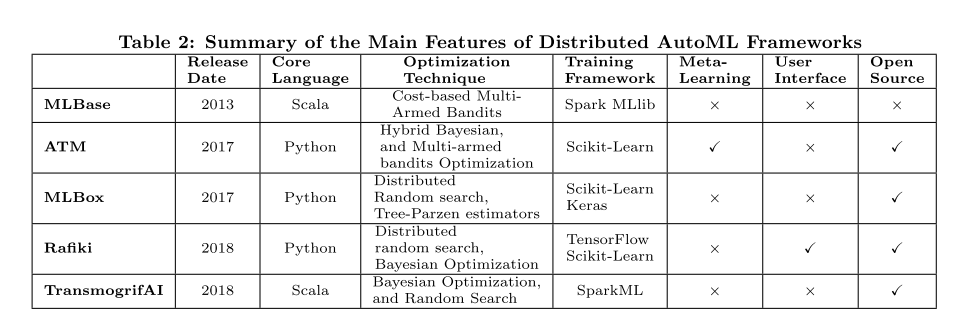
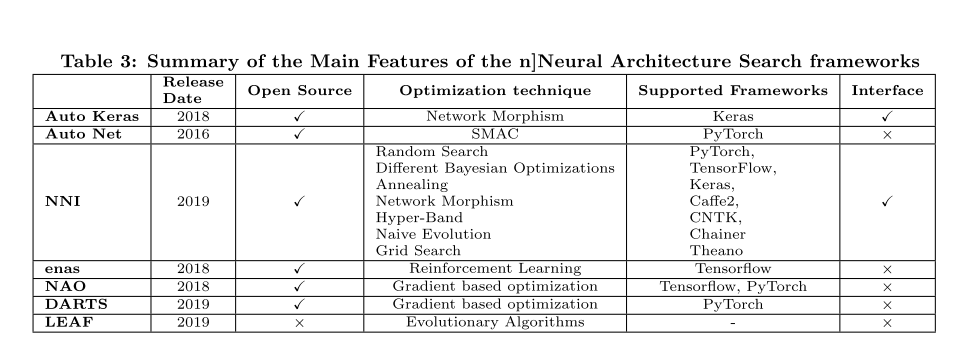
In fifth section, this paper covers the various tools and frameworks that have been implemented to tackle the CASH problem. In general, these tools and frameworks can be classified into three main categories: centralized, distributed, and cloud-based. And Neural Network Automation Frameworks is also a class recently.
在第五部分中,本文介绍了为解决CASH问题而实施的各种工具和框架。 这些工具和框架可以分为三大类:集中式框架,分布式框架和基于云平台的框架。此外,神经网络自动化框架也逐渐发展起来。
Sixth Section
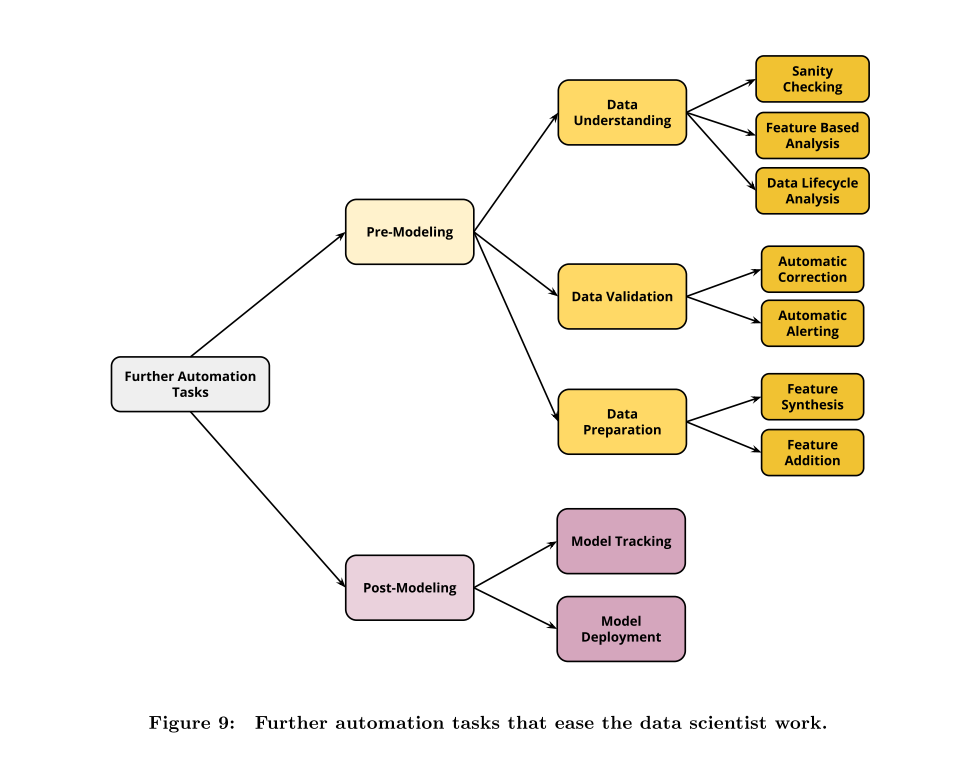
In sixth section, this paper introduces some state-of-the-art research efforts on tackling the automation aspects for the other building blocks (Pre-modeling and Post-Modeling) of the complex machine learning pipeline.
在第六部分中,本文介绍了一些关于自动化复杂机器学习问题中的其他构建模块(比如预建模和后建模)的前沿研究工作,。
Seventh Section
In seventh section, this paper introduces some research directions and challenges that need to be addressed in order to achieve the vision and goals of the AutoML process. It includes scalability, optimization techniques, time budget, composability, user friendliness, continuous delivery pipeline, data validation, data preparation, and model deployment and life cycle.
在第七部分中,本文介绍了为了实现AutoML过程的这个目标,需要进一步研究的的一些方向和挑战。它包括可扩展性,优化技术,时间预算,可组合性,用户友好性,持续交付管道,数据验证,数据准备,模型部署和生命周期。
Appendix Ⅰ : This Survey Mind map
Auto Machine Learning Survey Notes(Ⅲ)
Zöller, M.-A., & Huber, M. F. (2019). Survey on Automated Machine Learning. Retrieved from http://arxiv.org/abs/1904.12054
First Section
In first section, this paper introduces the history of AutoML, and shows AutoML is no new trend. It also gives this paper’s contributions: introduce a mathematical formulation covering the complete procedure of automatic ML pipeline creation, cover AutoML techniques for each step of building an ML pipeline, and evaluate all presented algorithms. Finally, it shows this paper’s structure.
在第一部分中,本文介绍了自动化机器学习的发展历史,并指出它并不是一个新的趋势。本文还给出了这篇论文的贡献:介绍了一个覆盖整个自动化机器学习过程的数学公式,介绍了构建机器学习流水线的每一步的automl技术,并对所提出的所有算法进行了评估。最后给出了这篇论文的脉络结构。
Second Section
In second section, this paper gives a mathematical sound formulation of the automatic construction of ML pipelines is given. And it shows most current state-of-the-art algorithms solve the pipeline creation problem in two distinct stages, pipeline structure search, and Algorithm selection and hyperparameters optimization.
第二部分给出了ML流水线自动构造的数学合理公式。并说明了目前最先进的算法如何解决了流水线创建问题,分为两个子问题,分别是流水线结构搜索和算法选择及超参数优化。
Third Section
In third section, this paper introduces some approaches about pipeline structure creation.
a basic ML pipeline layout:
- At first, the input data is cleaned in multiple distinct steps, like imputation of missing data and one-hot encoding of categorical input.
- Next, relevant features are selected and new features created in a feature engineering stage. This stage highly depends on the underlying domain.
- Finally, a single model is trained on the previously selected features.
a fixed pipeline shape:
Fixed ML pipeline used by most AutoML frameworks. Minor differences exist regarding the implemented data cleaning steps. Regarding data cleaning, the pipeline shape differs. Yet, often the two steps imputation and scaling are implemented.
Even though this approach greatly reduces the complexity of the pipeline creation problem, it leads to inferior pipeline performances for complex data sets.
Fixed shaped ML pipelines lack this flexibility to adapt to a specific task.
some variable shapes:
- genetic programming, Genetic programming is an iterative, domain-agnostic optimization method derived from biological evolution.
- hierarchical task networks(HTNs),HTNs are a method from automated planning that recursively partition a complex problem into easier subproblems.
- self-play, Self-play (Lake et al., 2017) is a reinforcement learning strategy, the algorithm creates new training examples by playing against itself. A common drawback of self-play approaches is the low convergence speed making this approach rather unsuited for AutoML.
第三部分介绍了一些关于机器学习流水线创建的方法。
首先介绍了一个基本的机器学习流水线布局,在这个布局里,输入数据先被清洗,然后从中提取出特征,最后,根据提取出的特征训练模型。
之后,介绍了固定的流水线布局,这个布局被大部分自动化机器学习框架采用。这个布局与基本的机器学习流水线布局相比,只有在数据清洗的步骤有所差异。在该布局中,数据清洗是由两个步骤完成的,插补和缩放。尽管这种布局极大地减少了流水线创建的复杂度,但它也使得流水线在处理复杂的数据集时性能不高。而且,这种布局还缺乏适应特定任务的灵活性。
最后,介绍了一些流水线布局的变体。第一个是基于遗传编码的变体,这种方法是一中从生物进化借鉴而来的迭代优化方法;第二个是基于层次任务网络的方法,这种方法是一种自动地将复杂问题递归地划分为简单问题的方法。第三个是self-play方法,这个是一种强化学习的策略,这个方法通过与自身对抗创建新的训练示例,但是这个方法的一个常见缺点就是收敛速度低,因此它不是很适合autoML。
Fourth Section
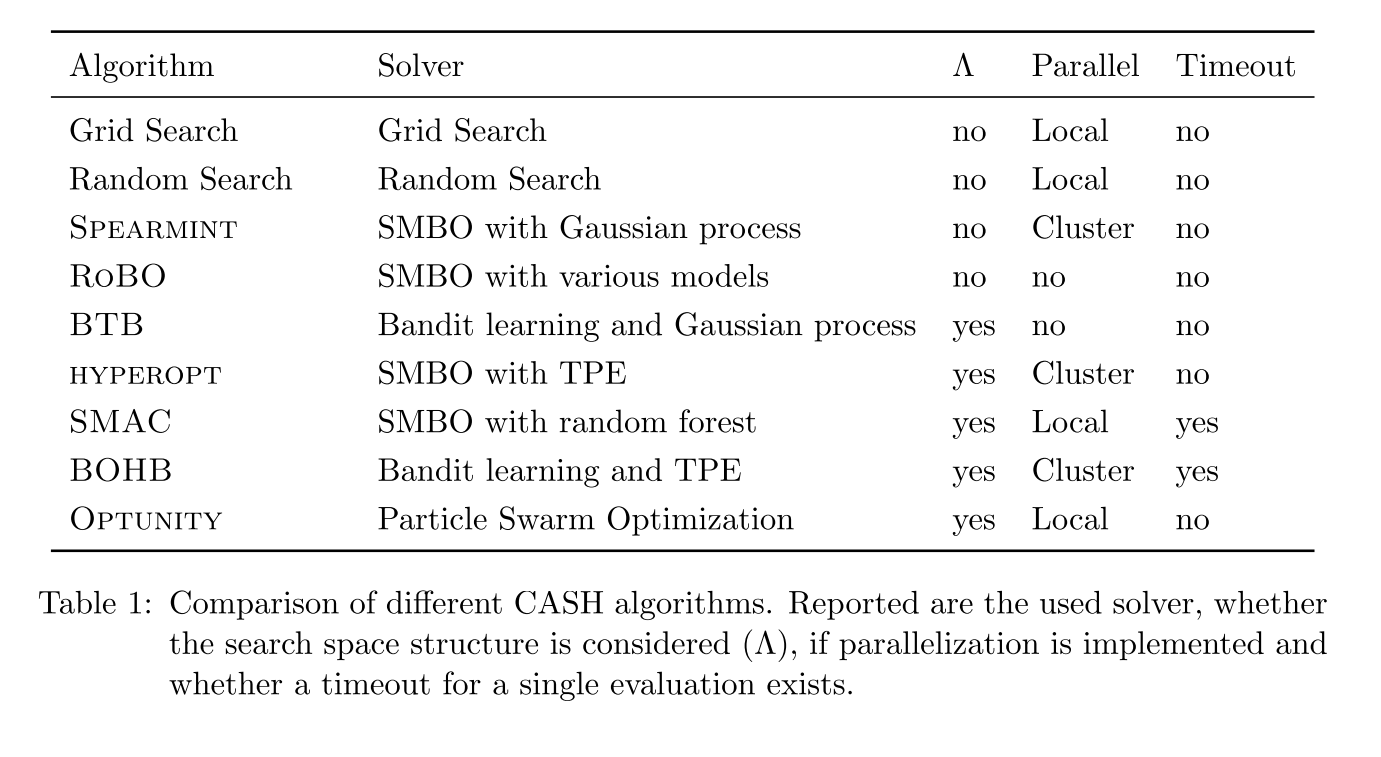
In fourth section, this paper shows some approaches to solve CASH problem (the combined algorithm selection and hyperparameter optimization, both steps are executed simultaneously) .
Grid Search, The first approach proposed to systematically explore the configuration space was grid search.
grid search creates a grid of configurations and evaluates all of them. Therefore, each continuous hyperparameter is discretized into k (logarithmic) equidistant values.
This basic algorithm does not scale well for large configuration spaces, as the number of function evaluations grows exponentially with the number of hyperparameters.
Random Search, A candidate configuration is generated by randomly choosing a value for each hyperparameter independently of all others.
Random search is straightforward to implement and parallelize and well suited for gradient-free functions with many local minima .
Sequential Model-Based Optimization:
- Gaussian Process, Even though a Gaussian process is a non-parametric model, it still requires hyperparameters itself, namely the selection of m and k. A common drawback of Gaussian processes is the runtime complexity of O(n3) due to the inversion of K.
- Random Forests, Random forest regression is an ensemble method consisting of multiple regression trees
- Tree-structured parzen estimator, TPE natively handles hierarchical search spaces by modeling each hyperparameter individually by two one-dimensional distributions.
Evolutionary Algorithm:
- Genetic Programming, genetic programming should only be used for CASH in combination with ML pipeline structure search. Because some concepts cannot be easily applied to algorithm selection: a crossover between a SVM and a decision tree cannot be modeled reasonably.
- Particle Swarm Optimization, PSO tends to converge faster to a local minimum in comparison to genetic programming .
Multi-Armed Bandit Learning, Multi-armed bandit learning is limited to a finite number of bandits.
Gradient Descent, A very powerful optimization method is gradient descent, an iterative minimization algorithm.
在第四部分,论文主要介绍了一些解决CASH问题的方法。
算法选择和超参数优化两个步骤同步进行,这个简称CASH问题。
- 网格搜索:这是第一个系统搜索配置空间的方法。网格搜索为配置创建了一个网格,并且对它们进行了评估。同时每一个连续的超参数都被等价地离散化为k个值。这个基础的算法不能很好地解决较大配置空间的问题,因为评估函数的数量将会随着超参数的数量指数级增长。
- 随机搜索:通过随机地为每一个独立的超参数选择一个值,便可以产生一个候选的配置,随机搜索很容易实现,也很容易并行化,非常适合具有许多局部最小值的无梯度函数。
- 基于序列模型的优化:
- 高斯过程:尽管一个高斯过程是一个无参数的模型,但它本身依旧需要超参数,比如m和k的选择。高斯过程一个普遍的缺点就是由于k的反转而导致的高时间复杂度O(n3)。
- 随机森林:随机森林回归是有多个回归树组成一个集成方法
- 树形结构的parzen估计:TPE通过两个一维分布分别对每个超参数进行建模,进而在本地处理分层搜索空间
- 进化算法:
- 遗传编码:遗传编码只能用于CASH和机器学习流水线结构查找相结合,因为某些概念不能轻易应用于算法选择:SVM和决策树之间的交叉无法合理地建模。
- 粒子群优化算法:和遗传编码相比,PSO更快地收敛到局部最小值。
- 多臂赌博机学习:仅限于有限数量的赌博机。
- 梯度下降法:基于迭代的最小化算法。
Fifth Section
Data cleaning is an important aspect of building an ML pipeline. The purpose of data cleaning is improving the quality of a data set by removing data errors. Common error classes are missing values in the input data, invalid values or broken links between entries of multiple data sets.
数据清理是构建ML流水线的一个重要方面。 数据清洗的目的通过消除数据错误来提高数据集的质量。 常见错误类别有输入数据中缺少的值,无效值或多个数据集的条目之间的连接缺失。
Sixth Section
The task of feature engineering is highly domain specific and very difficult to generalize. Even for a data scientist assessing the impact of a feature is difficult, as domain knowledge is necessary. Consequently, feature engineering is a mainly manual and time-consuming task driven by trial and error.
Feature selection is the easier part of feature engineering as the search space is very limited: each feature can either be included or excluded. Consequently, many different algorithms for feature selection exist.
Basically all automatic feature generation approaches follow the iterative scheme. Based on an initial data set, a set of candidate features is generated and ranked. High ranking features are evaluated and potentially added to the data set. These three steps are repeated several times.
特征工程的任务是和领域高度相关的,很难统一概括。 因此即使是数据科学家也很难对特征的优劣进行评估。 因此,特征工程是一个主要由人类参与且耗时巨大的试错过程。
特征选择是特征工程中比较容易的部分,因为搜索空间非常有限:可以包含或排除某个特征。 现在存在许多用于特征选择的不同算法。
而至于特征生成方面,基本上所有自动特征生成方法都遵循迭代方案。 基于初始数据集,生成并排列一组候选特征。 评估并对这些其中排序靠前的特征,并有可能添加到数据集中。 这三个步骤重复几次,直到生成符合要求的特征。
Seventh Section
In seventh section, this paper introduces different performance improvements.
- Multi-Fidelity Approximations: Depending on the used data set, fitting a single model can take several hours, in extreme cases even up to several days. Consequently, optimization progress is very slow. A common approach to circumvent this limitation is the usage of multi-fidelity approximations. By testing a configuration on this training subset, bad performing configurations can be discarded very fast and only well performing configurations have to be tested on the complete training set.
- Early Stopping: A quite simple approximation is aborting the fitting after the first fold if the performance is significantly worse than the current incumbent.
- Scalability: A common strategy for solving a computational heavy problem is parallelization on multiple cores or within a cluster. As AutoML normally has to fit many ML models, distributing different fitting instances in a cluster is an obvious idea.
- Ensemble Learning: Ensemble methods combine multiple ML models to create predictions. Depending on the diversity of the combined models, the overall accuracy of the predictions can be significantly increased. The cost of evaluating multiple ML models is often neglectable considering the performance improvements.
- Meta-Learning: Meta-learning can be used in multiple stages of automatically building an ML pipeline to increase the efficiency. Search Space Refinements, Filtering of Candidate Configurations, Warm-Starting, Pipeline Structure.
在第七部分,论文介绍了几种不同的优化方法,多保真估计,早停,扩展,集成学习和元学习。
- 多保真估计:通过测试该训练子集上的配置,可以非常快速地丢弃性能差的配置,并且只需要在完整的训练集上测试性能良好的配置。
- 早停: 一个非常简单的近似是在第一次折叠后如果性能明显比当前的差,那么中止拟合。
- 扩展:由于AutoML通常必须适合许多ML模型,因此在一个群集中分配不同的拟合实例是一个直接的想法。
- 集成学习:集成学习结合多个ML模型来进行预测。
- 元学习:元学习可以在自动构建ML流水线的多个阶段中使用,以提高效率。
Eighth Section
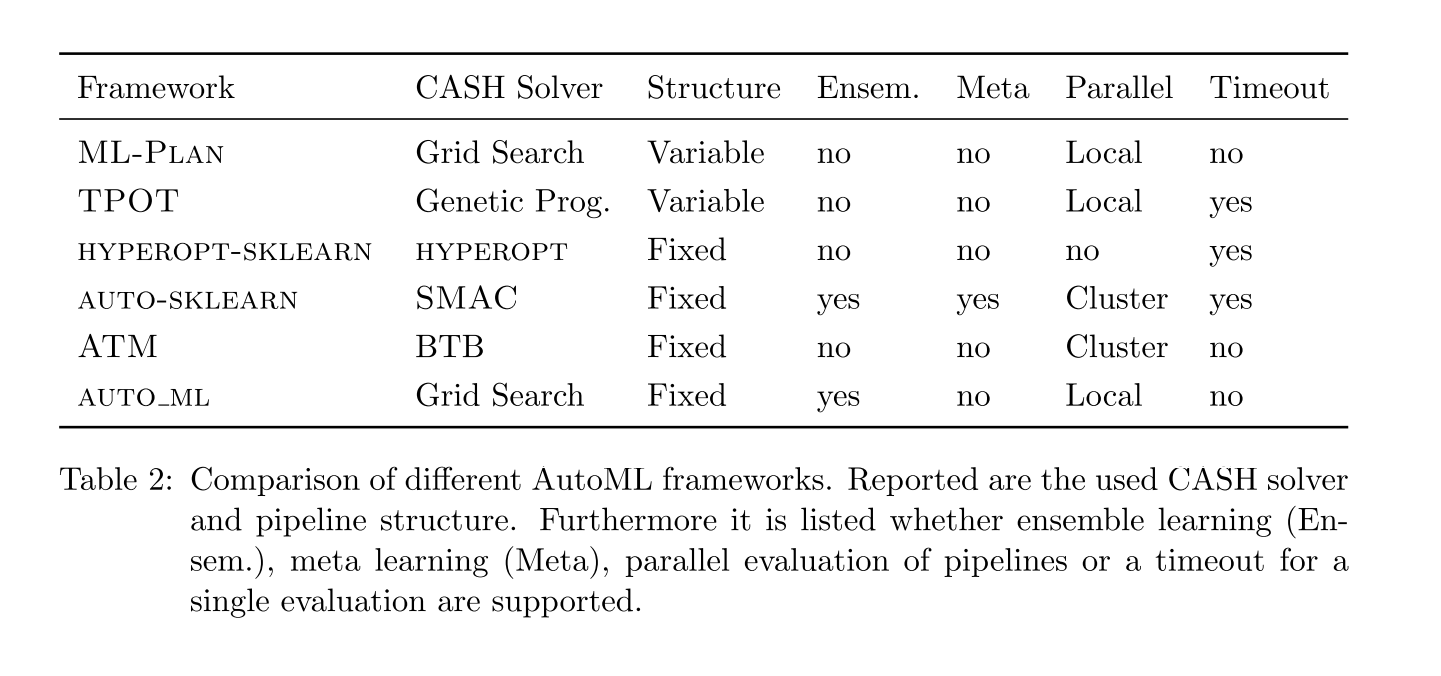
In this section, papers introduces some existing frameworks:
在第八部分,论文介绍了一些现有的框架。
Appendix Ⅰ:This Survey Mind map